
데이터 불러오기
데이터 분석을 위해 데이터를 불러오는 작업부터 해야 한다. 이때 불러오는 데이터를 '데이터 집합'이라고 한다.
그러면 데이터 집합을 불러오는 방법과 데이터를 간단히 살펴보자.
처음 불러올 데이터 집합은 갭마인더(Gapminder)이다.
판다스 라이브러리 임포트
import pandas as pd
갭마인더 데이터 집합 불러오기
df = pd.read_csv('../data/gapminder.tsv', sep='\t')read_csv() 함수를 이용하여 데이터를 불러오자. sep 속성값은 '\t'으로 구분되어 있음을 의미한다.
시리즈와 데이터프레임
판다스에서 사용되는 자료형은 시리즈(Series)와 데이터프레임(DataFrame)이 있다.
데이터프레임은 엑셀에서 볼 수 있는 시트(Sheet)와 동일한 개념이며 시리즈는 시트의 열 1개를 의미한다.
파이썬으로 비유하면 데이터프레임은 시리즈들이 각 요소가 되는 딕셔너리이다.
데이터 집합 살펴보기
read_csv() 메서드는 데이터 집합을 읽어 들여와 데이터프레임이라는 자료형으로 반환한다.
head() 메서드는 데이터 프레임에서 가장 앞에 있는 5개의 행을 출력하므로 데이터의 값을 볼 수 있다.
print(df.head())
df에 저장된 값이 정말 데이터프레임이라는 자료형인지 type을 봐보자.
print(type(df))
shape() 메서드를 이용하여 데이터의 행과 열의 크기에 대한 정보를 살펴보자.
print(df.shape)
열을 한번 살펴보자. columns 속성을 사용하면 데이터프레임의 열 이름을 확인할 수 있다.
print(df.columns)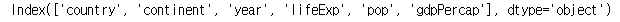
dtypes 속성이나 info 메서드로 데이터프레임을 구성하는 값의 자료형을 확인할 수 있다.
print(df.dtypes)
print(df.info())
판다스와 파이썬 자료형 비교

판다스는 문자열 자료형을 object라는 이름으로 인식하고 파이썬은 string으로 인식한다.
같은 자료형이라도 판다스, 파이썬이 서로 다른 이름으로 인식한다는 점을 주의 깊게 살펴봐야 한다.