
시리즈 만들기
판다스의 Series 메서드에 리스트를 전달하여 시리즈를 생성해보자.
import pandas as pd
s = pd.Series(['banana', 42])
print(s)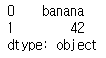
인덱스(index)는 보통 0부터 시작한다. 하지만 시리즈를 생성할 때 문자열을 인덱스로 지정할 수 있다.
s = pd.Series(['Wes McKinney', 'Creator of Pandas'])
print(s)
print()
s = pd.Series(['Wes McKinney', 'Creator of Pandas'], index=['Person', 'Who'])
print(s)
데이터프레임 만들기
데이터프레임을 만들기 위해서는 딕셔너리를 DataFrame 클래스에 전달해야 한다.
scientists = pd.DataFrame({
'Name' : ['Rosaline Franklin', 'William Gosset'],
'Occupation' : ['Chemist', 'Statistician'],
'Born' : ['1920-07-25', '1876-06-13'],
'Died' : ['1958-04-16', '1937-10-16'],
'Age' : [37, 61]
})
print(scientists)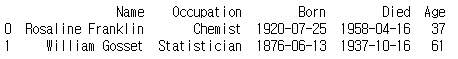
시리즈와 마찬가지로 데이터프레임도 인덱스를 따로 지정하지 않으면 인덱스를 0부터 자동으로 생성한다.
인덱스를 따로 지정하려면 index 속성에 리스트를 전달하면 된다.
또한 columns 속성에 열 이름을 원하는 순서로 전달하면 원하는 순서로 출력할 수 있다.
scientists = pd.DataFrame({
'Name' : ['Rosaline Franklin', 'William Gosset'],
'Occupation' : ['Chemist', 'Statistician'],
'Born' : ['1920-07-25', '1876-06-13'],
'Died' : ['1958-04-16', '1937-10-16'],
'Age' : [37, 61]
},
index=['Rosaline Franklin', 'William Goaset'],
columns=['Occupation', 'Born', 'Age', 'Died'])
print(scientists)
출력을 보면 Age의 순서가 달라진 것을 볼 수 있다. 또한 인덱스가 문자열로 변경된 것을 볼 수 있다.
딕셔너리는 데이터의 순서를 보장하지 않는다. 즉, Name의 Rosaline Franklin, William Goaset의 순서가 바뀔 수도 있다.
만약 순서가 보장된 딕셔너리를 전달하려면 OrderedDict 클래스를 사용해야 한다.
scientists = pd.DataFrame(OrderedDict([
('Name', ['Rosaline Franklin', 'William Gosset']),
('Occupation', ['Chemist', 'Statistician']),
('Born', ['1920-07-25', '1876-06-13']),
('Died', ['1958-04-16', '1937-10-16']),
('Age', [37, 61])
])
)
print(scientists)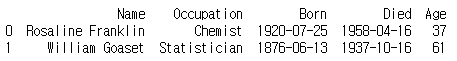
시리즈 다루기
먼저 scientists에 데이터프레임을 준비하자.
scientists = pd.DataFrame(
data={'Occupation' : ['Chemist', 'Statistician'],
'Born' : ['1920-07-25', '1876-06-13'],
'Died' : ['1958-04-16', '1937-10-16'],
'Age' : [37, 61]},
index=['Rosaline Franklin', 'William Gosset'],
columns=['Occupation', 'Born', 'Died', 'Age'])
print(scientists)데이터프레임에서 시리즈를 선택하려면 loc 속성에 인덱스를 전달하면 된다.
first_row = scientists.loc['William Gosset']
print(type(first_row))
print()
print(first_row)

Age열에 정수형 리스트를 전달해도 시리즈를 출력해 보면 시리즈의 자료형을 오브젝트로 인식한다.
시리즈 속성과 메서드 사용하기 - index, values, keys
loc, iloc와 같은 속성 외에도 시리즈에는 다양한 속성이 미리 정의되어 있다.
index 속성
시리즈의 인덱스가 들어 있다.
print(first_row.index)
print(first_row.index[0])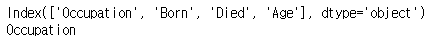
values 속성
시리즈의 데이터가 저장되어 있다.
print(first_row.values)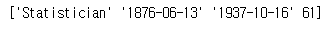
keys 속성
keys는 속성이 아니라 메서드이다. keys 메서드는 index 속성과 같은 역할을 한다.
print(first_row.keys())
print(first_row.keys()[0])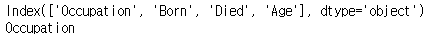
시리즈의 기초 통계 메서드 사용
ages = scientists['Age']
print(ages)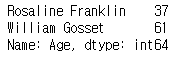
print(ages.mean())
print()
print(ages.min())
print()
print(ages.max())
print()
print(ages.std())

시리즈 다루기 - 응용
원하는 데이터를 추출할 때 특정 인덱스를 지정하여 추출했다. 하지만 보통은 추출할 데이터의 정확한 인덱스를 모르는 경우가 더 많다. 이런 경우에 사용하는 방법이 불린 추출이다.
데이터 불러오기
scientists = pd.read_csv('../data/scientists.csv')
최댓값과 평균값을 계산해보자.
ages = scientists['Age']
print(ages.max())
print()
print(ages.mean())
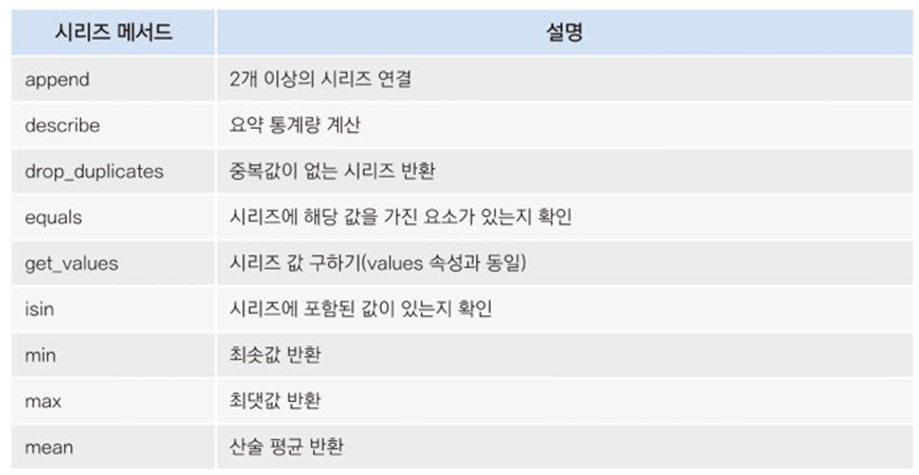
이제 불린 추출을 사용하자. 특정 조건을 설정하고 그 조건에 해당하는 데이터만 추출하는 방법이다.
print(ages[ages > ages.mean()])
ages의 평균보다 큰 데이터만 추출하도록 하였다.
먼저 ages > ages.maen()의 결과는 인덱스마다 bool으로 계산된다.
print(ages > ages.mean())
ages > ages.mean()의 결괏값의 개수가 여러 개다. 이렇게 시리즈나 데이터프레임에 있는 모든 데이터에 대해 한번에 연산하는 것을 브로드캐스팅(Broadcasting)이라 한다. 그리고 시리즈처럼 여러 개의 값을 가진 데이터를 벡터라고 하고 단순 크기를 나타내는 데이터를 스칼라라고 한다.
브로드캐스팅 수행
같은 길이의 벡터로 더하기 연산과 곱하기 연산을 수행한 것이다.
print(ages + ages)
print()
print(ages * ages)
만약 벡터에 스칼라를 연산하면 다음과 같다.
print(ages + 100)
또 길이가 다른 벡터를 서로 더하면 어떻게 될까
print(pd.Series([1, 100]))
print()
print(ages + pd.Series([1, 100]))
시리즈와 시리즈를 연산하는 경우 같은 인덱스의 값만 계산한다. 일치하지 않은 인덱스는 계산을 할 수 없어 NaN으로 출력된다.
데이터 정렬하기
rev_ages = ages.sort_index(ascending=False)
print(rev_ages)
ascending 인자로 False를 전달하여 인덱스 역순으로 데이터를 정렬할 수 있다.
만약 뒤집은 벡터와 기존 벡터를 더하면 어떻게 될까??
print(ages * 2)
print()
print(ages + rev_ages)
뒤집어서 더한 결과가 나올 거 같지만 연산은 인덱스가 일치하는 값끼리 연산하기 때문에 *2 연산과 동일한 결과가 나온다.
데이터프레임 다루기
데이터프레임도 불린 추출을 할 수 있다.
print(scientists[scientists['Age'] > scientists['Age'].mean()])
bool벡터를 가지고 데이터를 추출할 수도 있다.
print(scientists.loc[[True, True, False, True, False, True, True, True]])
길이가 맞지 않으면 에러가 발생한다.
시리즈와 마찬가지로 브로드캐스팅도 가능하다.
print(scientists * 2)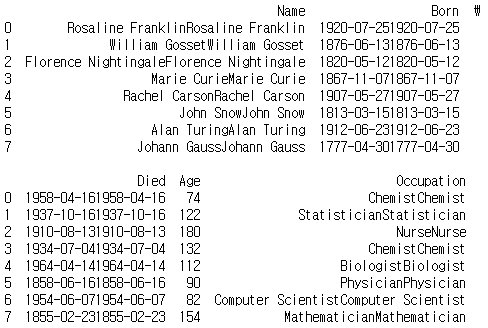
object는 같은 내용이 두배로 늘어난다.
시리즈 만들기
판다스의 Series 메서드에 리스트를 전달하여 시리즈를 생성해보자.
import pandas as pd
s = pd.Series(['banana', 42])
print(s)인덱스(index)는 보통 0부터 시작한다. 하지만 시리즈를 생성할 때 문자열을 인덱스로 지정할 수 있다.
s = pd.Series(['Wes McKinney', 'Creator of Pandas'])
print(s)
print()
s = pd.Series(['Wes McKinney', 'Creator of Pandas'], index=['Person', 'Who'])
print(s)
데이터프레임 만들기
데이터프레임을 만들기 위해서는 딕셔너리를 DataFrame 클래스에 전달해야 한다.
scientists = pd.DataFrame({
'Name' : ['Rosaline Franklin', 'William Gosset'],
'Occupation' : ['Chemist', 'Statistician'],
'Born' : ['1920-07-25', '1876-06-13'],
'Died' : ['1958-04-16', '1937-10-16'],
'Age' : [37, 61]
})
print(scientists)시리즈와 마찬가지로 데이터프레임도 인덱스를 따로 지정하지 않으면 인덱스를 0부터 자동으로 생성한다.
인덱스를 따로 지정하려면 index 속성에 리스트를 전달하면 된다.
또한 columns 속성에 열 이름을 원하는 순서로 전달하면 원하는 순서로 출력할 수 있다.
scientists = pd.DataFrame({
'Name' : ['Rosaline Franklin', 'William Gosset'],
'Occupation' : ['Chemist', 'Statistician'],
'Born' : ['1920-07-25', '1876-06-13'],
'Died' : ['1958-04-16', '1937-10-16'],
'Age' : [37, 61]
},
index=['Rosaline Franklin', 'William Goaset'],
columns=['Occupation', 'Born', 'Age', 'Died'])
print(scientists)출력을 보면 Age의 순서가 달라진 것을 볼 수 있다. 또한 인덱스가 문자열로 변경된 것을 볼 수 있다.
딕셔너리는 데이터의 순서를 보장하지 않는다. 즉, Name의 Rosaline Franklin, William Goaset의 순서가 바뀔 수도 있다.
만약 순서가 보장된 딕셔너리를 전달하려면 OrderedDict 클래스를 사용해야 한다.
scientists = pd.DataFrame(OrderedDict([
('Name', ['Rosaline Franklin', 'William Gosset']),
('Occupation', ['Chemist', 'Statistician']),
('Born', ['1920-07-25', '1876-06-13']),
('Died', ['1958-04-16', '1937-10-16']),
('Age', [37, 61])
])
)
print(scientists)
시리즈 다루기
먼저 scientists에 데이터프레임을 준비하자.
scientists = pd.DataFrame(
data={'Occupation' : ['Chemist', 'Statistician'],
'Born' : ['1920-07-25', '1876-06-13'],
'Died' : ['1958-04-16', '1937-10-16'],
'Age' : [37, 61]},
index=['Rosaline Franklin', 'William Gosset'],
columns=['Occupation', 'Born', 'Died', 'Age'])
print(scientists)데이터프레임에서 시리즈를 선택하려면 loc 속성에 인덱스를 전달하면 된다.
first_row = scientists.loc['William Gosset']
print(type(first_row))
print()
print(first_row)Age열에 정수형 리스트를 전달해도 시리즈를 출력해 보면 시리즈의 자료형을 오브젝트로 인식한다.
시리즈 속성과 메서드 사용하기 - index, values, keys
loc, iloc와 같은 속성 외에도 시리즈에는 다양한 속성이 미리 정의되어 있다.
index 속성
시리즈의 인덱스가 들어 있다.
print(first_row.index)
print(first_row.index[0])
values 속성
시리즈의 데이터가 저장되어 있다.
print(first_row.values)
keys 속성
keys는 속성이 아니라 메서드이다. keys 메서드는 index 속성과 같은 역할을 한다.
print(first_row.keys())
print(first_row.keys()[0])
시리즈의 기초 통계 메서드 사용
ages = scientists['Age']
print(ages)print(ages.mean())
print()
print(ages.min())
print()
print(ages.max())
print()
print(ages.std())
시리즈 다루기 - 응용
원하는 데이터를 추출할 때 특정 인덱스를 지정하여 추출했다. 하지만 보통은 추출할 데이터의 정확한 인덱스를 모르는 경우가 더 많다. 이런 경우에 사용하는 방법이 불린 추출이다.
데이터 불러오기
scientists = pd.read_csv('../data/scientists.csv')
최댓값과 평균값을 계산해보자.
ages = scientists['Age']
print(ages.max())
print()
print(ages.mean())이제 불린 추출을 사용하자. 특정 조건을 설정하고 그 조건에 해당하는 데이터만 추출하는 방법이다.
print(ages[ages > ages.mean()])ages의 평균보다 큰 데이터만 추출하도록 하였다.
먼저 ages > ages.maen()의 결과는 인덱스마다 bool으로 계산된다.
print(ages > ages.mean())ages > ages.mean()의 결괏값의 개수가 여러 개다. 이렇게 시리즈나 데이터프레임에 있는 모든 데이터에 대해 한번에 연산하는 것을 브로드캐스팅(Broadcasting)이라 한다. 그리고 시리즈처럼 여러 개의 값을 가진 데이터를 벡터라고 하고 단순 크기를 나타내는 데이터를 스칼라라고 한다.
브로드캐스팅 수행
같은 길이의 벡터로 더하기 연산과 곱하기 연산을 수행한 것이다.
print(ages + ages)
print()
print(ages * ages)
만약 벡터에 스칼라를 연산하면 다음과 같다.
print(ages + 100)
또 길이가 다른 벡터를 서로 더하면 어떻게 될까
print(pd.Series([1, 100]))
print()
print(ages + pd.Series([1, 100]))시리즈와 시리즈를 연산하는 경우 같은 인덱스의 값만 계산한다. 일치하지 않은 인덱스는 계산을 할 수 없어 NaN으로 출력된다.
데이터 정렬하기
rev_ages = ages.sort_index(ascending=False)
print(rev_ages)ascending 인자로 False를 전달하여 인덱스 역순으로 데이터를 정렬할 수 있다.
만약 뒤집은 벡터와 기존 벡터를 더하면 어떻게 될까??
print(ages * 2)
print()
print(ages + rev_ages)뒤집어서 더한 결과가 나올 거 같지만 연산은 인덱스가 일치하는 값끼리 연산하기 때문에 *2 연산과 동일한 결과가 나온다.
데이터프레임 다루기
데이터프레임도 불린 추출을 할 수 있다.
print(scientists[scientists['Age'] > scientists['Age'].mean()])
bool벡터를 가지고 데이터를 추출할 수도 있다.
print(scientists.loc[[True, True, False, True, False, True, True, True]])길이가 맞지 않으면 에러가 발생한다.
시리즈와 마찬가지로 브로드캐스팅도 가능하다.
print(scientists * 2)object는 같은 내용이 두배로 늘어난다.