누락값
누락값은 NaN, NAN, nan과 같은 방법으로 표기한다. 누락값은 0이나 ' '과는 다른 개념이다.
누락값은 말 그대로 데이터 자체가 없다는 것을 의미한다. db에서 null과 같은 개념이다.
따라서 같다는 개념도 없다.
from numpy import NaN, NAN, nan
print(NaN == True)
print()
print(NaN == False)
print()
print(NaN == 0)
print()
print(NaN == ' ')
또한 값 자체가 없기 때문에 NaN끼리 비교해도 같지 않다.
print(NaN == NaN)
print()
print(NaN == nan)
print()
print(NaN == NAN)
print()
print(nan == NAN)
누락값을 확인하려면 isnull 메서드를 사용하면 된다.
import pandas as pd
print(pd.isnull(NaN))
print()
print(pd.isnull(nan))
print()
print(pd.isnull(NAN))
print()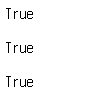
반대의 경우는 notnull 메서드를 사용하면 된다.
print(pd.notnull(NaN))
print()
print(pd.notnull(42))
print()
print(pd.notnull('missing'))
print()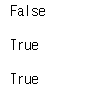
누락값이 생기는 이유
누락값은 처음부터 누락값이 있는 데이터를 불러오거나 데이터를 연결, 입력하는 등의 과정에서 생길 수 있다.
데이터를 불러와 알아보자.
visited = pd.read_csv('../data/survey_visited.csv')
visited = pd.read_csv('../data/survey_survey.csv')
print(visited)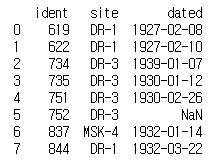
print(survey)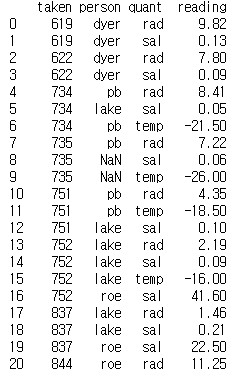
두 데이터프레임 모두 NaN을 포함하고 있다. 이를 연결해보자.
vs = visited.merge(survey, left_on='ident', right_on='taken')
print(vs)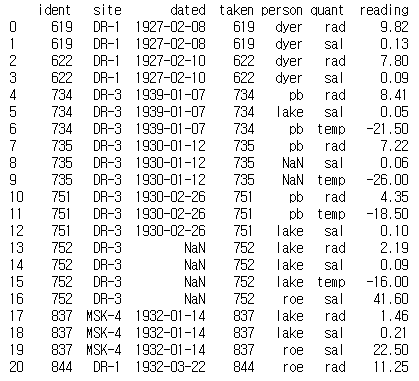
NaN값이 발생하는 것을 볼 수 있다.
데이터를 입력할 때 누락값이 생기는 경우를 봐보자. 시리즈를 생성할 때 데이터프레임에 없는 열과 행 데이터를 입력하면 누락값이 생긴다.
num_legs = pd.Series({'goat': 4, 'amoeba': nan})
print(num_legs)
scientists = pd.DataFrame({
'Name': ['Rosaline Franklin', 'William Gosset'],
'Occupation': ['Chemist', 'Statistician'],
'Born': ['1920-07-25', '1876-06-13'],
'Died': ['1958-04-16', '1937-10-16'],
'missing': [NaN, nan]
})
print(scientists)
범위를 지정하여 데이터를 추출할 때 누락값이 생길 수 있다.
데이터프레임에 존재하지 않는 데이터를 추출하면 누락값이 생긴다.
gapminder = pd.read_csv('../data/gapminder.tsv', sep='\t')
life_exp = gapminder.groupby(['year'])['lifeExp'].mean()
print(life_exp)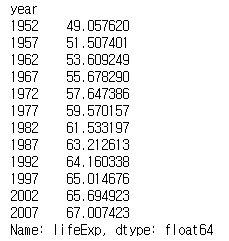
다음은 range 메서드를 이용하여 life_Exp 열에서 2000~2009년의 데이터를 추출한 것이다.
만약 2000~20009년까지의 데이터가 없다면 NaN이 발생하게 된다.
하지만 이제 없는 label은 지원하지 않아 에러가 발생한다.
print(life_exp.loc[range(2000, 2010), ])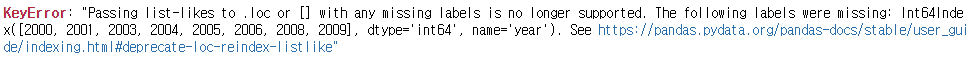
y2000 = life_exp[life_exp.index > 2000]
print(y2000)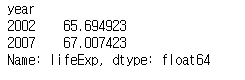
이런 식으로 2000 이상의 데이터만 추출할 수 있다.
누락값의 개수
누락값의 개수를 구하는 방법은 다음과 같다.
우선 데이터를 불러와 알아보자.
ebola = pd.read_csv('../data/country_timeseries.csv')print(ebola.count())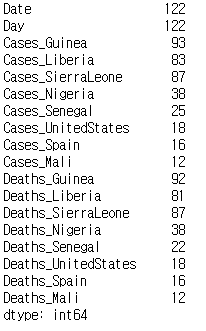
shape[0]에 전체 행의 데이터 개수가 저장되어 있다는 점을 이용하여 shape[0]에서 누락값이 아닌 값의 개수를 빼면 누락값의 개수를 구할 수 있다.
num_rows = ebola.shape[0]
num_missing = num_rows - ebola.count()
print(num_missing)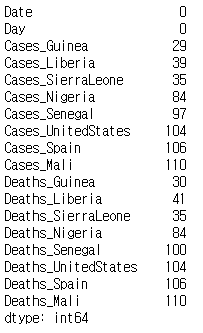
count_nonzero, isnull 메서드를 조합해도 누락값의 개수를 구할 수 있다.
import numpy as np
print(np.count_nonzero(ebola.isnull()))
print()
print(np.count_nonzero(ebola['Cases_Guinea'].isnull()))
value_counts 메서드는 지정한 열의 빈도를 구하는 메서드이다.
print(ebola.Cases_Guinea.value_counts(dropna=False).head())
누락값 변경하기
데이터프레임에 포함된 fillna 메서드에 0을 대입하면 누락값을 0으로 변경한다. fillna 메서드는 처리해야 하는 데이터프레임의 크기가 매우 크고 메모리를 효율적으로 사용해야 하는 경우에 자주 사용한다.
print(ebola.fillna(0).iloc[0:10, 0:5])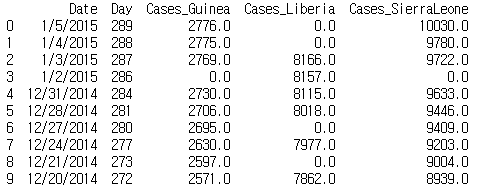
nan이 0으로 채워진 것을 볼 수 있다.
fillna 메서드의 method 인잣값을 ffill로 지정하면 누락값이 나타나기 전의 값으로 누락값이 변경된다.
예를 들어 6행에 누락값이 있다면 5행의 값으로 채운다. 하지만 그 전의 행이 없다면 그대로 NaN이다.
print(ebola.fillna(method='ffill').iloc[0:10, 0:5])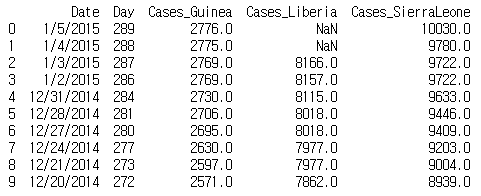
method 인잣값을 bfill로 지정하면 누락값이 나타난 이후의 첫 번째 값으로 앞쪽의 누락값이 모두 변경된다.
print(ebola.fillna(method='bfill').iloc[0:10, 0:5])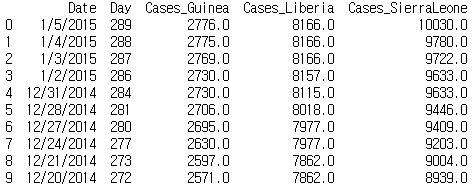
interpolate 메서드는 누락값 양쪽에 있는 값을 이용하여 중간값을 구한 다음 누락값을 처리한다.
이렇게 하면 데이터프레임이 일정한 간격을 유지하고 있는 것처럼 수정할 수 있다.
print(ebola.interpolate().iloc[0:10, 0:5])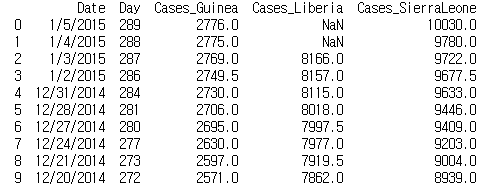
누락값 삭제하기
누락값이 필요 없는 경우에는 누락값을 삭제해도 된다. 하지만 누락값을 무작정 삭제하면 데이터가 너무 편향되거나 데이터의 개수가 너무 적어질 수 있다.
print(ebola.shape)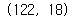
누락값을 삭제하기 위해 dropna 메서드를 사용할 수 있다.
ebola_dropna = ebola.dropna()
print(ebola_dropna.shape)
print()
print(ebola_dropna)
누락값이 포함된 데이터 계산하기
누락값들이 존재하는 데이터를 계산하려면 어떻게 해야 할까?
ebola_subset = ebola.loc[:, ['Cases_Guinea', 'Cases_Liberia', 'Cases_SierraLeone', 'Cases_multiple']]
print(ebola_subset.head(n=10))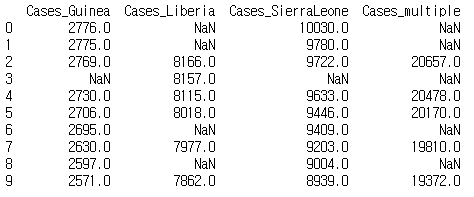
NaN이 포함된 데이터는 계산 결과가 NaN으로 나온다. 이를 방지하기 위해 sum 메서드를 사용해 합을 구할 수 있다.
skipna 인잣값을 True로 설정하면 누락값을 무시할 수 있다.
print(ebola.Cases_Guinea.sum(skipna = True))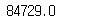
print(ebola.Cases_Guinea.sum(skipna = False))