
데이터 집계
보통 그룹 연산은 데이터를 '분할'하고 '반영'하고 '결합'하는 과정을 거치게 된다.
이를 '분할 - 반영 - 결합(Split - Apply - Combine)'이라고 한다.
groupby 메서드를 이용하여 뎅;터를 집계할 수 있다. 집계란 데이터에 평균을 구하거나 합을 구하는 등의 의미 있는 값을 도출해 내는 것을 말한다.
import pandas as pd
df = pd.read_csv('../data/gapminder.tsv', sep='\t')avg_life_exp_by_year = df.groupby('year').lifeExp.mean()
print(avg_life_exp_by_year)
groupby 메서드를 사용해 lifeExp 열의 연도별 평균값을 구했다.
groupby 메서드에 life 열을 전달하면 가장 먼저 연도별로 데이터를 나누는 과정이 진행된다.
year 열의 데이터를 중복없이 추출하는 '분할' 작업이 먼저 일어난다.
years = df.year.unique()
print(years)
그런 다음에는 연도별로 평균값을 구한다. 이 과정을 '반영'이라고 한다.
다음은 1952년도의 데이터를 다루는 과정이다.
y1952 = df.loc[df.year == 1952, :]
print(y1952.head())
print()
y1952_mean = y1952.lifeExp.mean()
print(y1952_mean)
이 과정을 모든 연도에 적용하면 '반영'작업이 끝난다.
df2 = pd.DataFrame({"year": [1952, 1957, 1962, 2007], "": [y1952_mean, y1957_mean, y1962_mean, y2007_mean]})
print(df2)
작업한 데이터를 합치는과정을 거치면 완료된다. 이를 '결합' 작업 이라 한다.
집계 메서드
다음은 자주 사용하는 메서드들을 정리한 표이다.

agg 메서드
라이브러리에서 제공하는 집계 메서드로 원하는 값을 계산할 수 없는 경우가 있다.
이럴 때는 직접 함수를 만들어서 사용한다. groupby 메서드와 사용자 함수를 조합하여 사용하려면 agg 메서드를 사용해야 한다.
def my_mean(values):
n = len(values)
sum = 0
for value in values:
sum += value
return sum / n평균을 구하는 함수를 만들어 보았다. 이를 agg 메서드를 사용하여 groupby 메서드와 조합해보자.
agg_my_mean = df.groupby('year').lifeExp.agg(my_mean)
print(agg_my_mean)
다음은 다른 함수의 예이다.
def my_mean_diff(values, diff_value):
n = len(values)
sum = 0
for value in values:
sum += value
mean = sum / n
return mean - diff_valueglobal_mean = df.lifeExp.mean()
print(global_mean)
print()
agg_mean_diff = df.groupby('year').lifeExp.agg(my_mean_diff, diff_value=global_mean)
print(agg_mean_diff)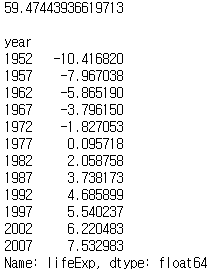
집계 메서드를 리스트와 딕셔너리에 담아 전달할 수 있다.
이제 위에 내용을 이용하여 응용해보자.
표준점수 계산
평균과 표준편차의 차이를 표준점수라고 부른다. 표준점수를 구하면 변환한 데이터의 평균값이 0이 되고 표준편차는 1이 된다.
def my_zscore(x):
return (x - x.mean()) / x.std()transform_z = df.groupby('year').lifeExp.transform(my_zscore)
print(transform_z.head())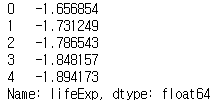
하지만 tranform은 데이터를 집계하는 것이 아니라 단순히 표준화할 뿐이다.
누락값을 평균값으로 처리
import seaborn as sns
import numpy as np
np.random.seed(42)
tips_10 = sns.load_dataset('tips').sample(10)
tips_10.loc[np.random.permutation(tips_10.index)[:4], 'total_bill'] = np.NaN
print(tips_10)
임의의 10개의 행을 가져온 뒤 4개의 값만 누락값으로 바꾼 것이다.
여기에 전체 데이터의 평균을 그대로 입력한다면 여성 데이터와 남성 데이터의 차이가 있어 데이터가 손상될 수 있다.
따라서 성별로 그룹화한 다음 평균값을 입력해야 한다.
def fill_na_mean(x):
avg = x.mean()
return x.fillna(avg)
total_bill_group_mean = tips_10.groupby('sex').total_bill.transform(fill_na_mean)
tips_10['fill_total_bill'] = total_bill_group_mean
print(tips_10)
데이터 필터링
만약 그룹화한 데이터에서 원하는 데이터를 걸러내고 싶다면 데이터 필터링을 사용하면 된다.
tips = sns.load_dataset('tips')
print(tips.shape)
print(tips['size'].value_counts())
size 열의 데이터를 보면 1, 5, 6 테이블의 주문이 매우 적다.
만약 이를 제외하고 싶다면 다음과 같이 하면 된다.
tips_filltered = tips.groupby('size').filter(lambda x: x['size'].count() >= 30)
print(tips_filltered)
print()
print(tips_filltered['size'].value_counts())

30번 이하인 1, 5, 6 테이블의 데이터를 제외시켰다.
그룹 오브젝트
groupby 메서드가 반환하는 값은 그룹 오브젝트이다.
tips_10 = sns.load_dataset('tips').sample(10, random_state=42)
print(tips_10)
grouped = tips_10.groupby('sex')
print(grouped)
print(grouped.groups)
그룹 오브젝트에 계산할 수 없는 값도 있지만 파이썬이 자동으로 계산할 수 있는 열을 골라 적용한다.
avgs = grouped.mean()
print(avgs)
특정 데이터만 추출하고 싶다면 get_group 메서드를 사용하면 된다.
female =grouped.get_group('Female')
print(female)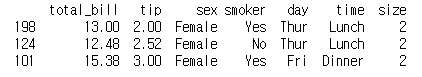
여러 열을 사용하여 그룹화
하나의 열로만 groupby 메서드를 적용할 수 있는 것은 아니다.
bill_sex_time = tips_10.groupby(['sex', 'time'])
group_avg = bill_sex_time.mean()
print(group_avg)
print()
print(type(group_avg))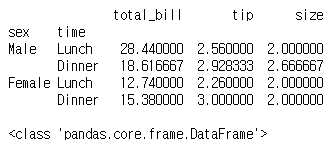
이 데이터프레임의 index를 초기화하여 정리해보자.
group_method = tips_10.groupby(['sex', 'time']).mean().reset_index()
print(group_method)
(groupby 메서드 사용할 때, as_index 인자를 False로 설정하면 같은 결과를 얻을 수 있다.)