
분석하기 좋은 데이터
분석하기 좋은 데이터란 데이터 집합을 분석하기 좋은 상태로 만들어 놓은 것을 말한다.
데이터 분석 단계에서 데이터 정리는 아주 중요하다. 실제로 데이터 분석 작업의 70% 이상을 차지하고 있는 작업이 데이터 정리 작업이다. 분석하기 좋은 데이터는 다음 조건을 만족해야 하고 이러한 데이터를 Tidy Data라고 한다.

데이터 연결
예를 들어 주식 데이터를 분석하는 과정에서 '기업 정보'가 있는 데이터 집합과 '주식 가격'이 있는 데이터 집합이 있을 때 '첨단 산업 기업의 주식 가격에 대한 데이터'를 보려면 어떻게 해야 할까??
일단 기업 정보에서 첨단 기술을 가진 기업을 찾아야 한다. 그리고 이 기업들의 주식 가격을 찾아야 한다.
그런 다음 찾아낸 2개의 데이터를 연결하면 된다. 이렇게 데이터 집합은 연관성이 깊은 값끼리 모여 있기 때문에 데이터 연결을 통해 필요한 데이터를 만드는 과정이 반드시 필요하다.
concat 메서드로 데이터 연결하기
우선 데이터를 로드하자.
import pandas as pd
df1 = pd.read_csv('../data/concat_1.csv')
df2 = pd.read_csv('../data/concat_2.csv')
df3 = pd.read_csv('../data/concat_3.csv')concat 메서드에 연결하려는 데이터프레임을 리스트에 담아 전달하면 연결한 데이터프레임을 반환한다.
concat 메서드는 데이터프레임을 연결할 때 위에서 아래 방향으로 연결한다. 그리고 df1, 2, 3은 열의 이름이 모두 A, B, C, D로 같아서 다음과 같이 유지된다.
row_concat = pd.concat([df1, df2, df3])
print(row_concat)
연결한 데이터프레임에서 행 데이터를 추출해보면 다음과 같다.
print(row_concat.iloc[3,])
concat 메서드는 전달받은 리스트의 요소 순서대로 데이터를 연결한다.
그래서 기존 데이터프레임에 있던 인덱스도 그대로 유지된다.
데이터프레임에 시리즈 연결하기
우선 리스트를 시리즈로 변환하자.
new_row_series = pd.Series(['n1', 'n2', 'n3', 'n4'])print(pd.concat([df1, new_row_series]))concat 메서드로 연결을 해보면 다음과 같은 출력이 나온다.

새로운 시리즈가 새로운 열로 추가되었다. NaN이라는 값도 많이 생겼다. 이 값을 누락값이라 하자.
만약 시리즈를 데이터프레임의 새로운 행으로 연결하려고 하면 어떻게 해야 할까?
시리즈에 열 이름을 부여하면 된다.
new_row_df = pd.DataFrame([['n1', 'n2', 'n3', 'n4']], columns=['A', 'B', 'C', 'D'])
print(new_row_df)
1개의 행을 가지는 데이터프레임을 생성했다. 이를 df1과 연결해보자.
print(pd.concat([df1, new_row_df]))
원하는 출력이 나왔다. 만약 연결할 데이터프레임이 1개라면 append 메서드를 사용해도 된다.
print(df1.append(new_row_df))
리스트가 아니라 딕셔너리를 이용하여 append 메서드를 사용하면 훨씬 간편하게 데이터를 연결할 수 있다.
data_dict={'A': 'n1', 'B': 'n2', 'C': 'n3', 'D': 'n4'}
print(df1.append(data_dict, ignore_index=True))
이때 ignore_index 인자를 True로 지정하면 이전에 사용하면 인덱스를 무시하고 다시 지정하게 된다.
ignore_index 인자는 concat 메서드에도 있다.
열 방향으로 데이터 연결하기
행 방향이 아니라 열 방향으로 데이터를 연결하고 싶다면 axis 인자를 1로 지정하면 된다.
col_concat = pd.concat([df1, df2, df3], axis=1)
print(col_concat)
다음과 같이 간편하게 새로운 열을 추가할 수도 있다.
col_concat['new_col_list'] = ['n1', 'n2', 'n3', 'n4']
print(col_concat)
열 방향으로 연결할 때 ignore_index 인자를 사용하면 열 이름을 0부터 다시 설정한다.
print(pd.concat([df1, df2, df3], axis=1, ignore_index=True))
공통 열과 공통 인덱스만 연결하기
만약 열 이름의 일부가 서로 다른 데이터프레임을 연결하면 어떻게 될까?
df1.columns = ['A', 'B', 'C', 'D']
df2.columns = ['E', 'F', 'G', 'H']
df3.columns = ['A', 'C', 'F', 'H']
row_concat = pd.concat([df1, df2, df3])
print(row_concat)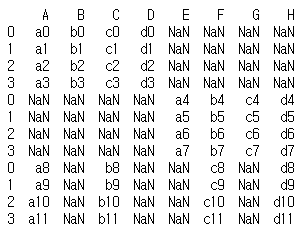
열 이름으로 정렬되며 연결된다. 하지만 데이터프레임에 없는 열 이름의 데이터는 누락값으로 처리된다.
공통인 열만 골라 연결하면 이 문제는 해결된다. 이때 join 인자를 inner로 지정하면 된다.
print(pd.concat([df1, df2, df3], join='inner'))
공통이 데이터가 없어서 Empty DataFrame이 된다.
두 개의 데이터프레임을 가지고 공통 열만 골라 연결해보자.
print(pd.concat([df1, df3], ignore_index=False, join='inner'))
판다스는 데이터 연결 전용 메서드인 merge를 제공한다.
merge 메서드 사용하기
우선 데이터를 불러오자.
person = pd.read_csv('../data/survey_person.csv')
site = pd.read_csv('../data/survey_site.csv')
survey = pd.read_csv('../data/survey_survey.csv')
visited = pd.read_csv('../data/survey_visited.csv')print(person)
print()
print(site)
print()
print(survey)
print()
print(visited)
print()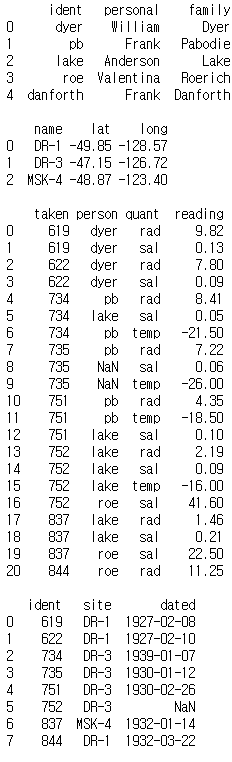
visited 데이터프레임의 일부 데이터만 떼어 실습에 사용하자.
visited_subset = visited.loc[[0, 2, 6], ]merge 메서드는 기본적으로 내부 조인을 실행하며 메서드를 사용한 데이터프레임을 왼쪽으로 지정하고 첫 번째 인잣값으로 지정한 데이터프레임을 오른쪽으로 지정한다. left_on, right_on 인자는 값이 일치해야 할 왼쪽과 오른쪽 데이터프레임의 열을 지정한다.
o2o_merge = site.merge(visited_subset, left_on='name', right_on='site')
print(o2o_merge)
m2o_merge = site.merge(visited, left_on='name', right_on='site')
print(m2o_merge)
ps = person.merge(survey, left_on='ident', right_on='person')
vs = visited.merge(survey, left_on='ident', right_on='taken')
print(ps)
print()
print(vs)
left_on, right_on에 전달하는 값은 여러 개라도 상관없다. 여러 개를 전달할 때는 리스트에 담아 전달하면 된다.
ps_vs = ps.merge(vs, left_on=['ident', 'taken', 'quant', 'reading'], right_on=['person', 'ident', 'quant', 'reading'])
print(ps_vs.loc[0])
_x는 왼쪽 데이터프레임의 열을, _y는 오른쪽 데이터프레임의 열을 의미한다.