
문제 설명
N개의 영단어들이 주어졌을 때, 가장 비슷한 두 단어를 구해내는 프로그램을 작성하시오.
두 단어의 비슷한 정도는 두 단어의 접두사의 길이로 측정한다. 접두사란 두 단어의 앞부분에서 공통적으로 나타나는 부분문자열을 말한다. 즉, 두 단어의 앞에서부터 M개의 글자들이 같으면서 M이 최대인 경우를 구하는 것이다. "AHEHHEH", "AHAHEH"의 접두사는 "AH"가 되고, "AB", "CD"의 접두사는 ""(길이가 0)이 된다.
접두사의 길이가 최대인 경우가 여러 개일 때에는 입력되는 순서대로 제일 앞쪽에 있는 단어를 답으로 한다. 즉, 답으로 S라는 문자열과 T라는 문자열을 출력한다고 했을 때, 우선 S가 입력되는 순서대로 제일 앞쪽에 있는 단어인 경우를 출력하고, 그런 경우도 여러 개 있을 때에는 그 중에서 T가 입력되는 순서대로 제일 앞쪽에 있는 단어인 경우를 출력한다.
https://www.acmicpc.net/problem/2179
제한 사항


풀이
문제를 요약하면, N개의 문자열이 주어질 때 최장 길이 접두사를 공유하는 두 단어를 출력하는 것이다.
즉, 앞에서부터 최대한 많이 일치하는 두 단어를 골라야 한다.
또한, 이러한 단어가 여러 개일 경우 입력된 순서가 빠른 단어를 우선으로 출력해야 한다.
해당 문제는 두 가지로 나눌 수 있다.
- 최장 길이의 접두사 구하기
- 최장 길이의 접두사를 가지는 두 단어를 입력 순서를 고려해 고르기
우선, 최장 길이의 접두사를 구하는 것은 어렵지 않다.
Trie를 사용해 문자열을 저장하면 접두사를 골라낼 수 있으며 이 길이를 비교해 최장 길이 접두사를 구할 수 있다.
Trie는 트리의 형태로 문자열을 저장하는 것이다.
예를 들어, abcd의 경우는 다음과 같다.
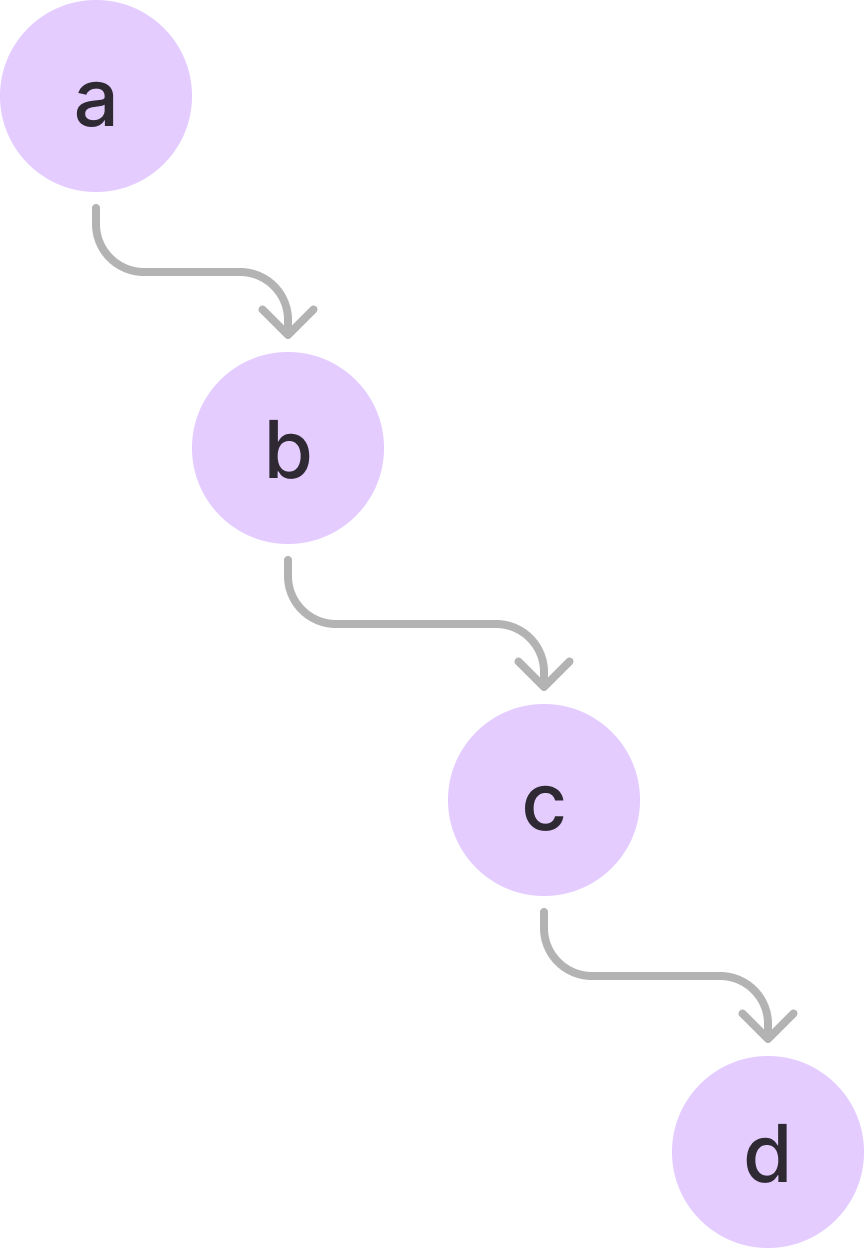
여기에 추가로 abe이라는 단어가 추가되면 다음과 같다.
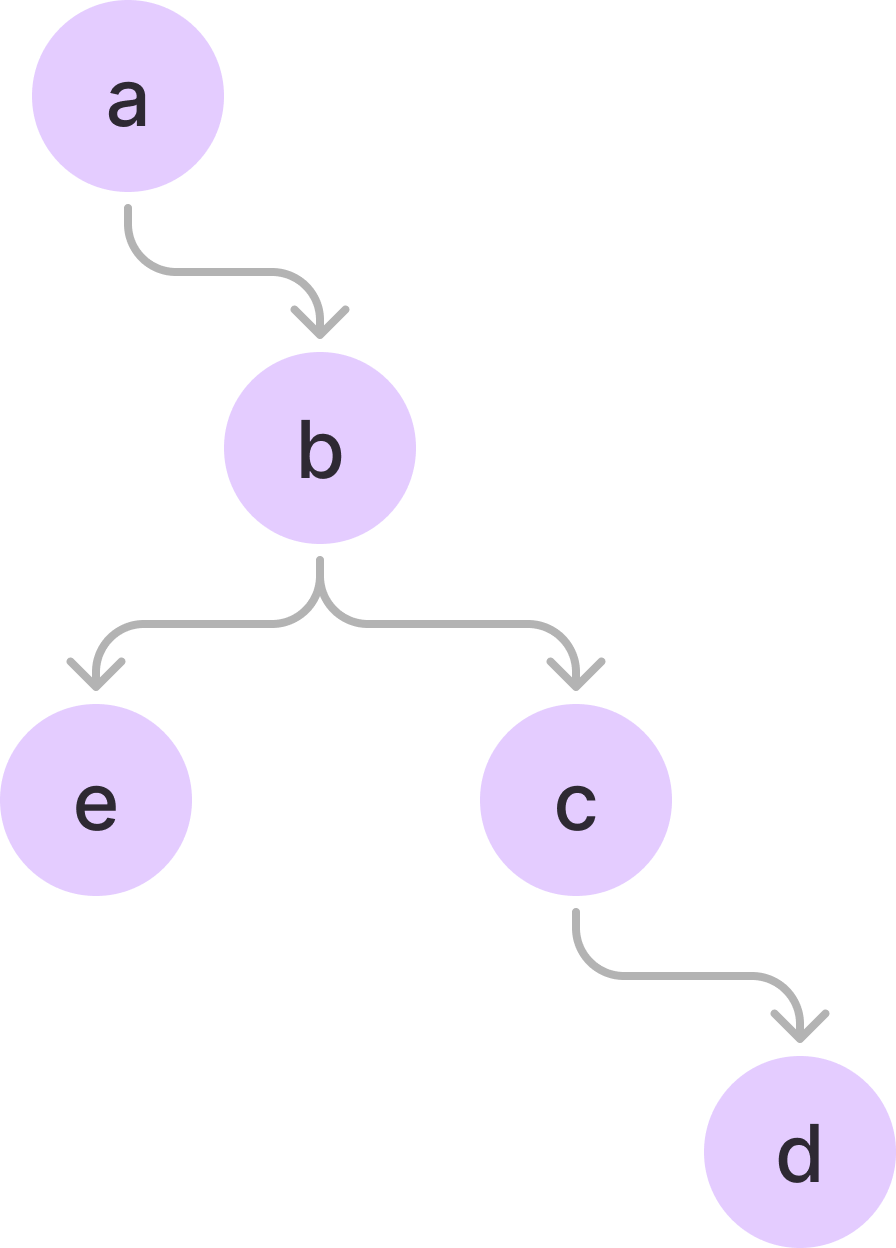
struct Node
{
char C;
Node* next[26] = {nullptr, };
int Idx;
Node() = default;
Node(char c, int i) : C(c), Idx(i) {};
};
이렇게 진행되면 접두사를 알아내기 쉬워진다.
abcd와 abe의 접두사는 ab이다.
이는 b에서 e를 추가하는 과정에서 판별해낼 수 있다.
b에서 e를 추가하려 할 때, e에는 노드가 존재하지 않는다.
즉, 해당 부분에서는 이전 abe를 가지는 이전 단어가 없다는 뜻으로 ab까지가 최장 길이의 접두사라는 뜻이 된다.
이렇게 접두사를 구했다면 최장 길이의 접두사를 유지하면 된다.
if (prefix.length() < temp.length())
{
prefix = temp;
first = prevIdx;
}
else if (prefix.length() == temp.length())
{
//먼저 나온 단어 기준
if (prevIdx < first)
{
prefix = temp;
first = prevIdx;
}
}
하지만, 문제는 같은 길이의 접두사가 있다면 입력 순서가 먼저 나온 게 우선시되어야 한다.
따라서, 해당 문자가 몇 번째 단어에서 추가된 것인지 기록하여 접두사의 순서를 정할 수 있다.
이렇게 입력 순서와 길이 등의 조건을 충족한 접두사가 정해졌다면 해당 접두사를 포함하는 두 단어를 찾아 출력하면 된다.
int cnt = 0;
for (auto& word : words)
{
bool bMatch = true;
for (int i = 0 ; i < prefix.length(); i++)
{
if (prefix[i] != word[i])
{
bMatch = false;
break;
}
}
if (bMatch)
{
cout << word << "\n";
cnt++;
}
if (cnt > 1) break;
}
전체 코드
#include <stdio.h>
#include <cstring>
#include <string>
#include <vector>
#include <algorithm>
#include <iostream>
#include <sstream>
#include <cmath>
#include <climits>
#include <queue>
#include <map>
#include <unordered_map>
#include <set>
#include <list>
#include <bitset>
using namespace std;
struct Node
{
char C;
Node* next[26] = {nullptr, };
int Idx;
Node() = default;
Node(char c, int i) : C(c), Idx(i) {};
};
int N;
vector<string> words;
Node* start;
string prefix;
const int MAX = 20'001;
int first = MAX;
void makeTrie(string word, int i)
{
Node* cursor = start;
string temp;
bool bPossible = true;
int prevIdx = MAX;
for (char c : word)
{
int idx = c - 'a';
if (cursor->next[idx] == nullptr)
{
cursor->next[idx] = new Node(c, i);
bPossible = false;
}
else
{
if (bPossible)
{
temp += c;
prevIdx = min(prevIdx, cursor->next[idx]->Idx);
}
}
cursor = cursor->next[idx];
}
if (prefix.length() < temp.length())
{
prefix = temp;
first = prevIdx;
}
else if (prefix.length() == temp.length())
{
//먼저 나온 단어 기준
if (prevIdx < first)
{
prefix = temp;
first = prevIdx;
}
}
}
int main()
{
ios_base::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
cin >> N;
start = new Node();
for (int i = 0; i < N; i++)
{
string word;
cin >> word;
words.push_back(word);
makeTrie(word, i);
}
int cnt = 0;
for (auto& word : words)
{
bool bMatch = true;
for (int i = 0 ; i < prefix.length(); i++)
{
if (prefix[i] != word[i])
{
bMatch = false;
break;
}
}
if (bMatch)
{
cout << word << "\n";
cnt++;
}
if (cnt > 1) break;
}
return 0;
}
문제 설명
N개의 영단어들이 주어졌을 때, 가장 비슷한 두 단어를 구해내는 프로그램을 작성하시오.
두 단어의 비슷한 정도는 두 단어의 접두사의 길이로 측정한다. 접두사란 두 단어의 앞부분에서 공통적으로 나타나는 부분문자열을 말한다. 즉, 두 단어의 앞에서부터 M개의 글자들이 같으면서 M이 최대인 경우를 구하는 것이다. "AHEHHEH", "AHAHEH"의 접두사는 "AH"가 되고, "AB", "CD"의 접두사는 ""
접두사의 길이가 최대인 경우가 여러 개일 때에는 입력되는 순서대로 제일 앞쪽에 있는 단어를 답으로 한다. 즉, 답으로 S라는 문자열과 T라는 문자열을 출력한다고 했을 때, 우선 S가 입력되는 순서대로 제일 앞쪽에 있는 단어인 경우를 출력하고, 그런 경우도 여러 개 있을 때에는 그 중에서 T가 입력되는 순서대로 제일 앞쪽에 있는 단어인 경우를 출력한다.
https://www.acmicpc.net/problem/2179
제한 사항
풀이
문제를 요약하면, N개의 문자열이 주어질 때 최장 길이 접두사를 공유하는 두 단어를 출력하는 것이다.
즉, 앞에서부터 최대한 많이 일치하는 두 단어를 골라야 한다.
또한, 이러한 단어가 여러 개일 경우 입력된 순서가 빠른 단어를 우선으로 출력해야 한다.
해당 문제는 두 가지로 나눌 수 있다.
- 최장 길이의 접두사 구하기
- 최장 길이의 접두사를 가지는 두 단어를 입력 순서를 고려해 고르기
우선, 최장 길이의 접두사를 구하는 것은 어렵지 않다.
Trie를 사용해 문자열을 저장하면 접두사를 골라낼 수 있으며 이 길이를 비교해 최장 길이 접두사를 구할 수 있다.
Trie는 트리의 형태로 문자열을 저장하는 것이다.
예를 들어, abcd의 경우는 다음과 같다.
여기에 추가로 abe이라는 단어가 추가되면 다음과 같다.
struct Node
{
char C;
Node* next[26] = {nullptr, };
int Idx;
Node() = default;
Node(char c, int i) : C(c), Idx(i) {};
};
이렇게 진행되면 접두사를 알아내기 쉬워진다.
abcd와 abe의 접두사는 ab이다.
이는 b에서 e를 추가하는 과정에서 판별해낼 수 있다.
b에서 e를 추가하려 할 때, e에는 노드가 존재하지 않는다.
즉, 해당 부분에서는 이전 abe를 가지는 이전 단어가 없다는 뜻으로 ab까지가 최장 길이의 접두사라는 뜻이 된다.
이렇게 접두사를 구했다면 최장 길이의 접두사를 유지하면 된다.
if (prefix.length() < temp.length())
{
prefix = temp;
first = prevIdx;
}
else if (prefix.length() == temp.length())
{
//먼저 나온 단어 기준
if (prevIdx < first)
{
prefix = temp;
first = prevIdx;
}
}
하지만, 문제는 같은 길이의 접두사가 있다면 입력 순서가 먼저 나온 게 우선시되어야 한다.
따라서, 해당 문자가 몇 번째 단어에서 추가된 것인지 기록하여 접두사의 순서를 정할 수 있다.
이렇게 입력 순서와 길이 등의 조건을 충족한 접두사가 정해졌다면 해당 접두사를 포함하는 두 단어를 찾아 출력하면 된다.
int cnt = 0;
for (auto& word : words)
{
bool bMatch = true;
for (int i = 0 ; i < prefix.length(); i++)
{
if (prefix[i] != word[i])
{
bMatch = false;
break;
}
}
if (bMatch)
{
cout << word << "\n";
cnt++;
}
if (cnt > 1) break;
}
전체 코드
#include <stdio.h>
#include <cstring>
#include <string>
#include <vector>
#include <algorithm>
#include <iostream>
#include <sstream>
#include <cmath>
#include <climits>
#include <queue>
#include <map>
#include <unordered_map>
#include <set>
#include <list>
#include <bitset>
using namespace std;
struct Node
{
char C;
Node* next[26] = {nullptr, };
int Idx;
Node() = default;
Node(char c, int i) : C(c), Idx(i) {};
};
int N;
vector<string> words;
Node* start;
string prefix;
const int MAX = 20'001;
int first = MAX;
void makeTrie(string word, int i)
{
Node* cursor = start;
string temp;
bool bPossible = true;
int prevIdx = MAX;
for (char c : word)
{
int idx = c - 'a';
if (cursor->next[idx] == nullptr)
{
cursor->next[idx] = new Node(c, i);
bPossible = false;
}
else
{
if (bPossible)
{
temp += c;
prevIdx = min(prevIdx, cursor->next[idx]->Idx);
}
}
cursor = cursor->next[idx];
}
if (prefix.length() < temp.length())
{
prefix = temp;
first = prevIdx;
}
else if (prefix.length() == temp.length())
{
//먼저 나온 단어 기준
if (prevIdx < first)
{
prefix = temp;
first = prevIdx;
}
}
}
int main()
{
ios_base::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
cin >> N;
start = new Node();
for (int i = 0; i < N; i++)
{
string word;
cin >> word;
words.push_back(word);
makeTrie(word, i);
}
int cnt = 0;
for (auto& word : words)
{
bool bMatch = true;
for (int i = 0 ; i < prefix.length(); i++)
{
if (prefix[i] != word[i])
{
bMatch = false;
break;
}
}
if (bMatch)
{
cout << word << "\n";
cnt++;
}
if (cnt > 1) break;
}
return 0;
}