
모델 튜닝
사이킷런의 SGDClassifier 클래스를 이용하여 로지스틱 회귀 문제에 경사 하강법을 적용했다.
이때 loss 함수를 log로 지정했었다.
from sklearn.datasets import load_breast_cancer
from sklearn.model_selction import train_test_split
cancer = load_breast_cancer()
x = cancer.data
y = cancer.target
x_train_all, x_test, y_train_all, y_test = train_test_split(x, y, stratify = y, test_size=0.2, random_state=42)
train_test_split() 함수를 이용하여 데이터를 나눌 수 있다.
임의로 데이터를 나누면 한쪽으로 데이터가 치우치거나 할 수 있다.
따라서, 이런 함수를 이용하여 나누어 주면 나중에 정확도가 증가한다.
하이퍼 파라미터(hyperparameter)
loss함수와 같은 매개변수의 값은 가중치나 절편처럼 알아서 학습되는 것이 아니다.
사용자가 직접 지정해야 하는 매개변수이다. 이것을 하이퍼 파라미터라고 한다.
성능
테스트 세트는 실전에 투입된 모델의 성능을 측정하기 위해 사용된다.
그런데 테스트 세트로 모델을 튜닝하면 테스트 세트에 대해서만 좋은 성능을 보여주는 모델이 만들어진다.
모델이 비슷한 문제를 달달 외운다고 생각하면 된다.
이런 현상을 '테스트 세트의 정보가 모델에 새어 나갔다'라고 말한다. 또는 일반화 성능이 왜곡됐다고 한다.
검증 세트
모델을 튜닝할 때 테스트 세트를 사용하지 않으면 된다.
그래도 모델을 튜닝하려면 성능 점수가 필요하다. 따라서, 새로운 데이터 세트를 만들어 검증에 사용한다.
이를 검증 세트(validation set)이라고 한다.

사실 분할비율은 6 : 2 : 2는 아니다.
8 : 2로 훈련 세트와 테스트 세트를 나눈 뒤, 훈련 세트를 다시 8 : 2로 훈련 세트와 검증 세트로 만든다.
데이터 전처리와 특성의 스케일
실전에서 수집된 데이터는 스케일이 들쭉날쭉하고 누락되지 않았다는 보장도 없다.
따라서, 데이터를 적절히 가공하는 '데이터 전처리'가 필요하다.
특성의 스케일은 알고리즘에 영향을 준다.
| 당도 | 무게 | |
| 사과1 | 4 | 540 |
| 사과2 | 8 | 700 |
| 사과3 | 2 | 480 |
당도와 무게의 스케일 차이가 많이 발생한다.
이런 경우 '두 특성의 스케일 차이가 크다'라고 말합니다.
이런 상황에서는 학습이 제대로 이루어지지 않을 경우가 있다.
가중치를 기록할 변수와 학습률 파라미터 추가
SingleLayer클래스에 변수를 추가하여 학습을 관리해보자.
def __init__(self):
self.w = None
self.b = None
self.losses = []
self.w_history = []
self.lr = learning_ratew_history는 가중치를 기록하는 변수이다.
learning_rate는 하이퍼 파라미터이다.
가중치의 업데이트 양을 조절할 목적으로 사용된다. 학습률에 따라 최적의 해를 구하는 과정이 달라질 수 있다.
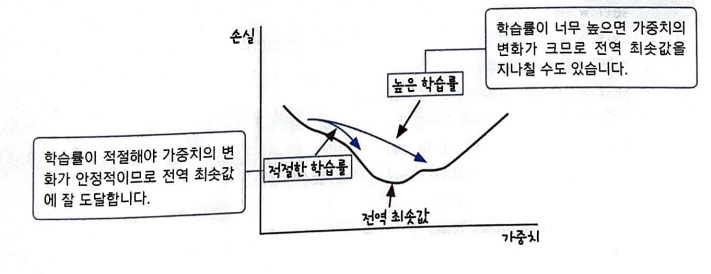
학습률이 너무 커도 작아도 안정적인 학습이 불가능하다.
보통 0.001, 0.01등의 로그 스케일로 학습률을 지정한다.
스케일이 다른 특성의 학습과정의 예시는 다음과 같다.
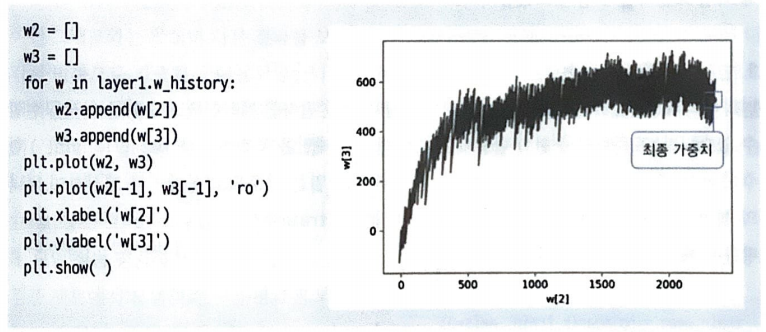
w[2]의 스케일은 0~2500이고, w[3]의 스케일은 0~700이기 때문에 상대적으로 작은 w[3]의 값이 크게 변동된다.
이런 현상을 스케일 조정으로 줄일 수 있다.
스케일 조정
스케일을 조정하는 방법은 많지만 신경망에서 자주 사용하는 방법은 표준화이다.
평균을 빼고 표준 편차로 나누면 되는 간단한 방법이다.
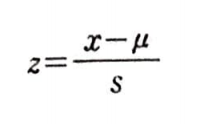
이때, 훈련 세트 검증 세트의 스케일을 같이 맞춰야 한다.
만약 하나라도 빼먹으면 성능이 매우 안 좋을 수 있다.
그리고 훈련 세트와 검증 세트를 같은 비율로 조정해야 한다.
즉, 훈련 세트의 평균과 표준 편차로 모두 표준화해야 한다는 뜻이다. 만약 따로따로 한다면 검증 세트의 샘플 데이터를 잘못 인식하게 된다.