
다층 신경망
하나의 층에 여러 개의 뉴런을 사용하면 신경망이 어떻게 달라질까??
입력층에서 전달되는 특성이 각 뉴런에 모두 전달될 것이다. 이를 'Dense'하다고 표현한다.
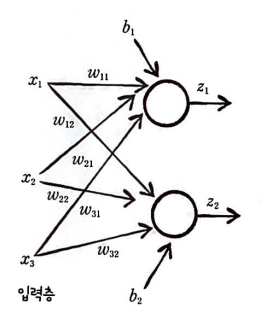
정방향 계산이 진행되는 과정부터 알아보자.
3개의 특성과 2개의 뉴런이 있는 경우이다.
모두 입력층에서 특성을 전달받아 z1, z2의 출력을 내놓는다.
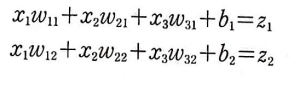
이를 행렬 곱셈으로 표현하면 다음과 같다.

가중치 행렬의 크기는 (입력의 개수, 출력의 개수)로 생각하면 된다,
현재 3개의 입력과 2개의 출력이 나오는 형태이기 때문에 (3, 2) 크기를 갖는다.
출력 통합
breast_cancer 데이터 세트는 binary 한 출력을 낸다. 즉, 악성인지 정상인지 판단하는 문제이다.
따라서 이진 분류 문제이므로 각 뉴런에서 출력된 값(z1, z2...)을 하나의 뉴런으로 다시 모아야 한다.
데이터 1개의 샘플에는 여러 특성의 값을 각 뉴런에 통과시키면 여러 개의 출력 값 (a1, a2,....)이 나오는데, 이 값들 중
하나만 골라 이진 분류에 적용할 수는 없다. 따라서 기준값을 만들어야 한다.
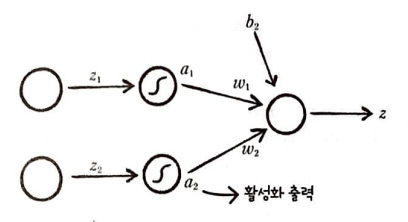
활성화 함수에 통과시켜 a를 얻은 뒤 마지막 뉴런에 입력하여 다시 z를 만든다.
이를 선형 방성식과 행렬 곱샘 표현으로 바꾸면 다음과 같다.
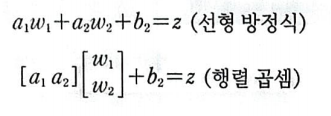
위에 내용을 모두 합쳐서 표현하면 다음과 같은 구조가 된다.
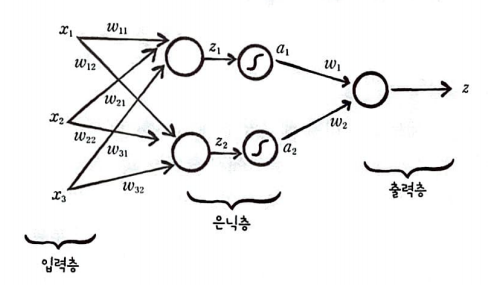
입력값이 모여 있는 층은 입력층이라 부르고, 이는 층의 개수에 포함시키지 않는다.
입력층의 값들은 출력층으로 전달되기 전에 2개의 뉴런으로 구성된 은닉층을 통과한다.
여기에는 절편(b)가 포함되지 않았는데 그림이 복잡해지기 때문에 보통은 생략한다.
신경망 확장
2개의 뉴런이 아닌 m개로 늘리면 어떻게 될까??
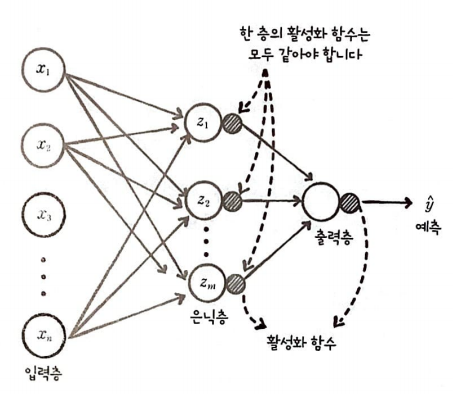
n개의 입력이 m개의 뉴런으로 입력된다. 그리고 은닉층을 통과하여 다시 출력층으로 모인다.
바로 이것이 딥러닝이다.
여기서 몇 가지 주의 사항과 개념을 정리해 보자.
- 활성화 함수는 층마다 다를 수 있지만 한 층에서는 같아야 한다.
각 층은 하나 이상의 뉴런을 가지는데, 은닉층과 출력층에 있는 모든 뉴런에는 활성화 함수가 필요하며 문제에 맞는 활성화 함수를 사용해야 한다. - 모든 뉴런이 연결되어 있으면 완전 연결 신경망이라고 한다.
입력층, 은닉층, 출력층 사이의 뉴런들이 모두 연결되어 있다면 이를 완전 연결(fully-connected)라고 한다.
다층 신경망에 경사 하강법 적용
다층 신경망에 경사 하강법을 적용하면 다음과 같다.
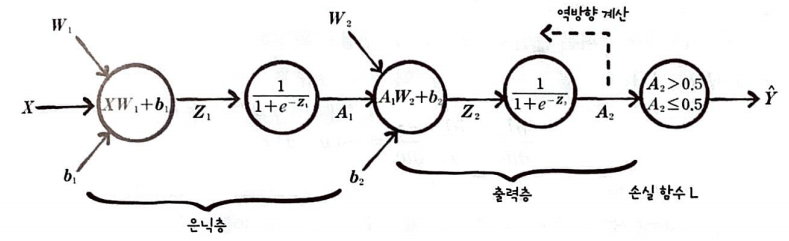
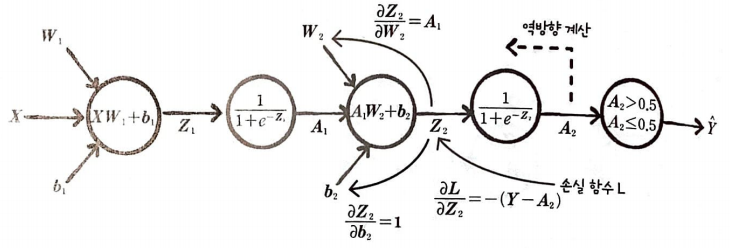
W2, b2 그리고 W1, b1에 대한 손실 함수 L의 도함수를 구해야 한다.
미분 순서는 출력층에서 은닉층 방향이며 손실 함수 L은 로지스틱 손실 함수이다.
가중치에 대하여 손실 함수 미분(출력층):
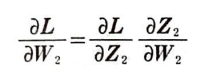
그림으로 표현하면 다음과 같다.
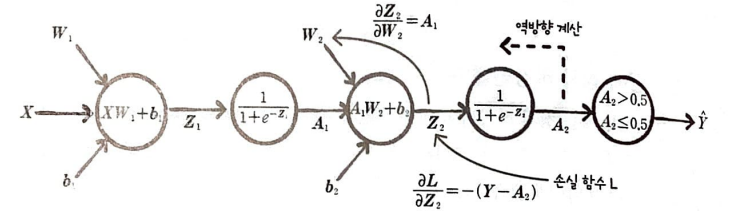
우리는 이미 답을 안다.
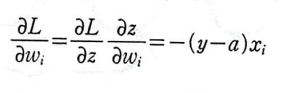
전에 사용했던 도함수를 행렬로 확장했다고 생각하면 된다.
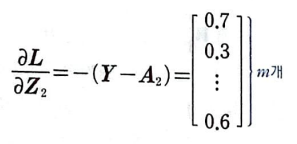
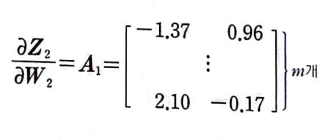
A1의 첫 번째 열은 첫 번째 뉴런의 활성화 출력이다. 이 열은 각 샘플이 만든 오차와 곱한 다음 모두 더하면 첫 번째 뉴런에 대한 그레이디언트의 총 합이 된다.
A1의 크기는 (m, 2)이다. -(Y - A2)의 크기는 (m, 1)이므로 A1을 전치하여 -(Y - A2)와 곱해야 한다.
그 결과로 W2 (2, 1)을 얻을 수 있다.
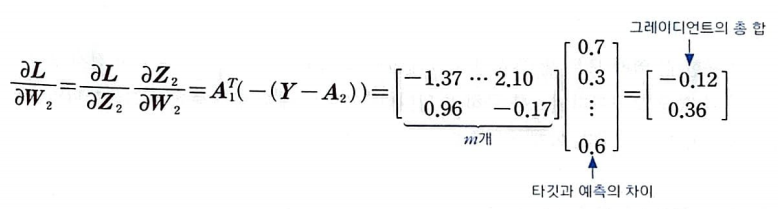
현재 구한 그레이디언트 행렬은 모든 샘플에 대한 그레이디언트의 총합이므로 가중치 행렬을 업데이트하기 위해서는 평균 그레이디언트를 구해야 한다.
그다음 적절한 학습률을 곱하여 가중치 행렬 W2를 업데이트하면 된다.
절편에 대한 손실 함수를 미분(출력층):
Z2를 절편에 대하여 미분하면 1이다. 이 또한 저번에 구한 도함수를 행렬로 확장한 것이다.
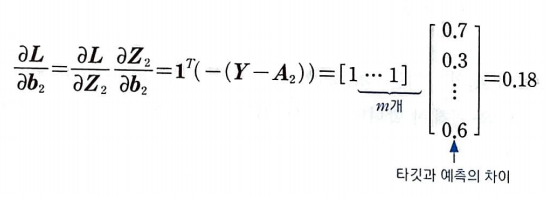
가중치에 대하여 손실 함수를 미분(은닉층):
가중치 W1에 대하여 손실 함수를 미분하면 다음과 같다.
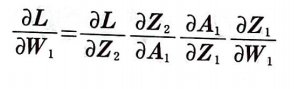
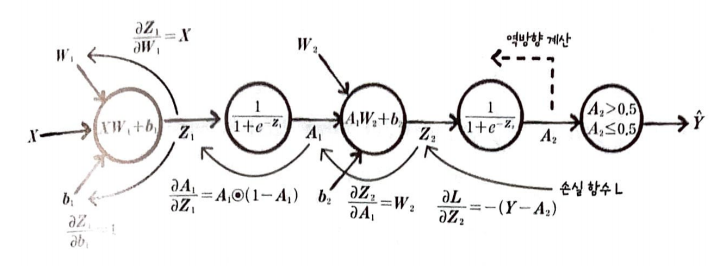
Z1을 W1에 의해 미분하면 X이다.
특성이 3개라면 (m, 3) 크기의 행렬을 생각하면 된다.
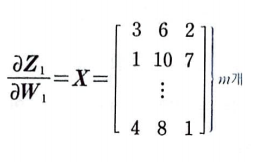
A1을 Z1에 의해 미분하면 미분하면 A1⦿(1 - A1)가 된다. (⦿은원 소별 곱셈이다)
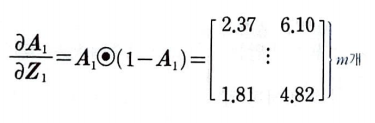
Z2를 A1에 의해 미분하면 W2이다. 크기는 (2, 1)이다.
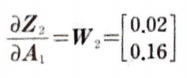
L을 Z2에 미분하면 -(Y - A2)이다.
종합하면 다음과 같다.



(3, 2) 크기의 그레이디언트 행렬을 얻을 수 있다.
절편에 대하여 손실 함수를 미분(은닉층):
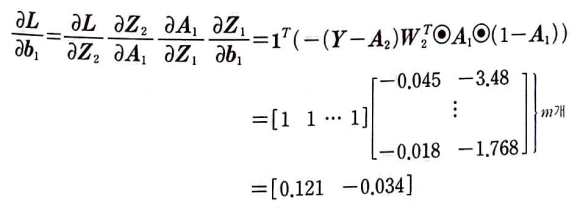
2개의 층을 가진 신경망 구현
SingleLayer를 상속한 DualLayer클래스를 만들어 보자.
class DualLayer(SingleLayer):
def __init__(self, units=10, learning_rate=0.1, l1=0, l2=0):
self.units = units #은닉층 뉴런 개수
self.w1 = None #은닉층 가중치
self.b1 = None #은닉층 절편
self.w2 = None #출력층 가중치
self.b2 = None #출력층 절편
self.a1 = None #은닉층 활성화 출력
self.losses = [] #훈련 손실
self.val_losses = [] #검승 손실
self.lr = learning_rate #학습률
self.l1 = l1 #l1 규제
self.l2 = l2 #l2 규제
생성자로 변수를 생성한다.
forpass() 수정
def forpass(self, x):
z1 = np.dot(x, self.w1) + self.b1 #첫 번쨰 층 선형식 계산
self.a1 = self.activation(z1) #활성화 함수
z2 = np.dot(self.a1, self.w2) + self.b2 #두번째 선형식 계산
return z2
은닉층의 활성화 함수를 통과한 a1과 출력층의 가중치 w2를 곱하고 b2를 더하여 최종 출력 z2를 반환한다.
backprop() 수정
def backprop(self, x, err):
m = len(x) #샘플 개수
w2_grad = np.dot(self.a1.T, err) / m #출력층 그레이디언트
b2_grad = np.num(err) / m
err_to_hidden = np.dot(err, self.w2.T) * self.a1 * (1 - self.a1) #시그모이드 그레이디언트 계산
w1_grad = np.dot(x.T, err_to_hidden) / m #은닉층 그레이디언트
b1_grad = np.sum(err_to_hidden) / m
return w1_grad, b1_grad, w2_grad, b2_grad 앞서 구한 공식을 코드로 표현한 것이다.
err_to_hidden은 가중치와 절편에서의 식이 동일하여 미리 값을 구해 계산과정을 간단하게 만들어 낸 것이다.
fit() 수정
def init_weights(self, n_featuers):
self.w1 = np.ones((n_featuers, self.units)) #(특성 개수, 은닉층 크기)
self.b1 = np.zeros(self.units) #은닉층 크기
self.w2 = np.ones((self.units, 1)) #(은닉층 크기,1)
self.b2 = 0
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
y = y.reshape(-1, 1)
y_val = y_val.reshape(-1, 1)
m = len(x)
self.init_weights(x.shape[1]) #가중치 초기화
for i on range(epochs):
a = self.training(x, y, m)
a = np.clip(a, 1e-10,1-1e-10) #클리핑
loss = np.sum(-(y*np.log(a) + (1-y)*np.log(1-a))) #로그 손실 추가
self.losses.append((loss + self.reg_loss()) / m)
self.update_val_loss(x_val, y_val)
def training(self, x, y, m):
z = self.forpass(x) #정방향 계산
a = self.activation(z) #활성화 함수
err = -(y - a) #오차 계산
w1_grad, b1_grad, w2_grad, b2_grad = self.backprop(x, err)
#그레이디언트 규제
w1_grad += (self.l1 * np.sign(self.w1) + self.l2 * self.w1) / m
w2_grad += (self.l1 * np.sign(self.w2) + self.l2 * self.w2) / m
#은닉층 가중치 절편 업데이트
self.w1 -= self.lr * w1_grad
self.b1 -= self.lr * b1_grad
#출력층 가중치 절편 업데이트
self.w2 -= self.lr * w2_grad
self.b2 -= self.lr * b2_grad
return a코드가 길어지고 가독성을 위해 가중치, 절편 초기화 함수와 훈련 코드를 분리하였다.
reg_loss() 수정
def reg_loss(self):
#은닉층과 출력층의 가중치에 규제 적용
return self.l1 * (np.sum(np.abs(self.w1)) + np.sum(np.abs(self.w2))) + self.l2 / 2 * (np.sum(self.w1**2) + np.sum(self.w2**2))
훈련 및 테스트

그래프로 분석해보자.
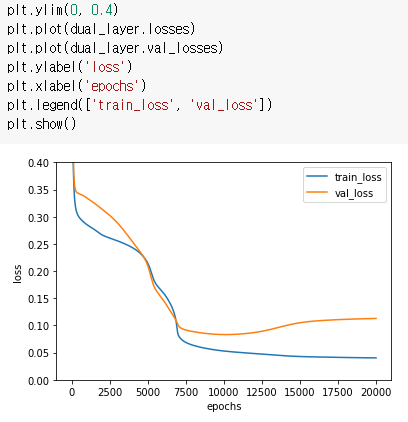
손실 그래프가 이전보다 천천히 감소한다.
SingleLayer 클래스보다 가중치의 개수가 훨씬 많아져 학습하는 데 시간이 오래 걸리기 때문이다.
breast_cancer데이터의 특성은 30개이므로 가중치 30개 절편 1개가 필요하지만,
DualLater 클래스에서는 뉴런(units)이 10개였으므로 30*10개의 가중치와 10개의 절편이 필요하고
출력층 역시 10개의 가중치와 1개의 절편이 필요하다. 총 321개의 가중치를 학습해야 한다.
가중치 초기화 개선
손실 그래프를 보면 초기 손실 값이 감소하는 곡선이 매끄럽지 않다.
아마도 손실 함수가 감소하는 방향을 올바르게 찾는 데 시간이 많이 소요된 것 같다.
가중치를 1로 놓고 훈련을 했던 것을 np.random.normal()을 이용하여 정규 분포를 따르는 무작위 수로 가중치를
초기화해보자.
class RandomInitNetwork(DualLayer):
def init_weights(self, n_featuers):
np.random.seed(42)
self.w1 = np.random.normal(0, 1, (n_featuers,self.units)) #(특성 개수, 은닉층 크기)
self.b1 = np.zeros(self.units) #은닉층 크기
self.w2 = np.random.normal(0, 1, (self.units, 1)) #(은닉층 크기, 1)
self.b2 = 0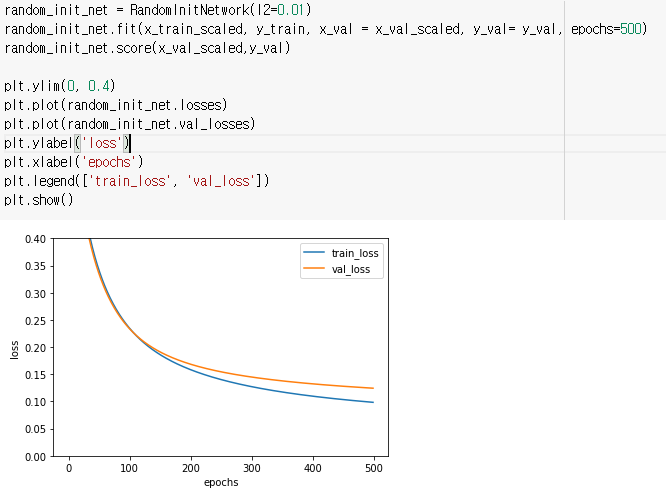
손실 함수가 감소하는 곡선이 매끄럽게 바뀌었다.
가중치를 1로 초기화했을 때 보다 훨씬 빠르게 손실 함숫값이 줄어들었다.
다층 신경망
하나의 층에 여러 개의 뉴런을 사용하면 신경망이 어떻게 달라질까??
입력층에서 전달되는 특성이 각 뉴런에 모두 전달될 것이다. 이를 'Dense'하다고 표현한다.
정방향 계산이 진행되는 과정부터 알아보자.
3개의 특성과 2개의 뉴런이 있는 경우이다.
모두 입력층에서 특성을 전달받아 z1, z2의 출력을 내놓는다.
이를 행렬 곱셈으로 표현하면 다음과 같다.
가중치 행렬의 크기는 (입력의 개수, 출력의 개수)로 생각하면 된다,
현재 3개의 입력과 2개의 출력이 나오는 형태이기 때문에 (3, 2) 크기를 갖는다.
출력 통합
breast_cancer 데이터 세트는 binary 한 출력을 낸다. 즉, 악성인지 정상인지 판단하는 문제이다.
따라서 이진 분류 문제이므로 각 뉴런에서 출력된 값(z1, z2...)을 하나의 뉴런으로 다시 모아야 한다.
데이터 1개의 샘플에는 여러 특성의 값을 각 뉴런에 통과시키면 여러 개의 출력 값 (a1, a2,....)이 나오는데, 이 값들 중
하나만 골라 이진 분류에 적용할 수는 없다. 따라서 기준값을 만들어야 한다.
활성화 함수에 통과시켜 a를 얻은 뒤 마지막 뉴런에 입력하여 다시 z를 만든다.
이를 선형 방성식과 행렬 곱샘 표현으로 바꾸면 다음과 같다.
위에 내용을 모두 합쳐서 표현하면 다음과 같은 구조가 된다.
입력값이 모여 있는 층은 입력층이라 부르고, 이는 층의 개수에 포함시키지 않는다.
입력층의 값들은 출력층으로 전달되기 전에 2개의 뉴런으로 구성된 은닉층을 통과한다.
여기에는 절편(b)가 포함되지 않았는데 그림이 복잡해지기 때문에 보통은 생략한다.
신경망 확장
2개의 뉴런이 아닌 m개로 늘리면 어떻게 될까??
n개의 입력이 m개의 뉴런으로 입력된다. 그리고 은닉층을 통과하여 다시 출력층으로 모인다.
바로 이것이 딥러닝이다.
여기서 몇 가지 주의 사항과 개념을 정리해 보자.
- 활성화 함수는 층마다 다를 수 있지만 한 층에서는 같아야 한다.
각 층은 하나 이상의 뉴런을 가지는데, 은닉층과 출력층에 있는 모든 뉴런에는 활성화 함수가 필요하며 문제에 맞는 활성화 함수를 사용해야 한다. - 모든 뉴런이 연결되어 있으면 완전 연결 신경망이라고 한다.
입력층, 은닉층, 출력층 사이의 뉴런들이 모두 연결되어 있다면 이를 완전 연결(fully-connected)라고 한다.
다층 신경망에 경사 하강법 적용
다층 신경망에 경사 하강법을 적용하면 다음과 같다.
W2, b2 그리고 W1, b1에 대한 손실 함수 L의 도함수를 구해야 한다.
미분 순서는 출력층에서 은닉층 방향이며 손실 함수 L은 로지스틱 손실 함수이다.
가중치에 대하여 손실 함수 미분(출력층):
그림으로 표현하면 다음과 같다.
우리는 이미 답을 안다.
전에 사용했던 도함수를 행렬로 확장했다고 생각하면 된다.
A1의 첫 번째 열은 첫 번째 뉴런의 활성화 출력이다. 이 열은 각 샘플이 만든 오차와 곱한 다음 모두 더하면 첫 번째 뉴런에 대한 그레이디언트의 총 합이 된다.
A1의 크기는 (m, 2)이다. -(Y - A2)의 크기는 (m, 1)이므로 A1을 전치하여 -(Y - A2)와 곱해야 한다.
그 결과로 W2 (2, 1)을 얻을 수 있다.
현재 구한 그레이디언트 행렬은 모든 샘플에 대한 그레이디언트의 총합이므로 가중치 행렬을 업데이트하기 위해서는 평균 그레이디언트를 구해야 한다.
그다음 적절한 학습률을 곱하여 가중치 행렬 W2를 업데이트하면 된다.
절편에 대한 손실 함수를 미분(출력층):
Z2를 절편에 대하여 미분하면 1이다. 이 또한 저번에 구한 도함수를 행렬로 확장한 것이다.
가중치에 대하여 손실 함수를 미분(은닉층):
가중치 W1에 대하여 손실 함수를 미분하면 다음과 같다.
Z1을 W1에 의해 미분하면 X이다.
특성이 3개라면 (m, 3) 크기의 행렬을 생각하면 된다.
A1을 Z1에 의해 미분하면 미분하면 A1⦿(1 - A1)가 된다. (⦿은원 소별 곱셈이다)
Z2를 A1에 의해 미분하면 W2이다. 크기는 (2, 1)이다.
L을 Z2에 미분하면 -(Y - A2)이다.
종합하면 다음과 같다.
(3, 2) 크기의 그레이디언트 행렬을 얻을 수 있다.
절편에 대하여 손실 함수를 미분(은닉층):
2개의 층을 가진 신경망 구현
SingleLayer를 상속한 DualLayer클래스를 만들어 보자.
class DualLayer(SingleLayer):
def __init__(self, units=10, learning_rate=0.1, l1=0, l2=0):
self.units = units #은닉층 뉴런 개수
self.w1 = None #은닉층 가중치
self.b1 = None #은닉층 절편
self.w2 = None #출력층 가중치
self.b2 = None #출력층 절편
self.a1 = None #은닉층 활성화 출력
self.losses = [] #훈련 손실
self.val_losses = [] #검승 손실
self.lr = learning_rate #학습률
self.l1 = l1 #l1 규제
self.l2 = l2 #l2 규제
생성자로 변수를 생성한다.
forpass() 수정
def forpass(self, x):
z1 = np.dot(x, self.w1) + self.b1 #첫 번쨰 층 선형식 계산
self.a1 = self.activation(z1) #활성화 함수
z2 = np.dot(self.a1, self.w2) + self.b2 #두번째 선형식 계산
return z2
은닉층의 활성화 함수를 통과한 a1과 출력층의 가중치 w2를 곱하고 b2를 더하여 최종 출력 z2를 반환한다.
backprop() 수정
def backprop(self, x, err):
m = len(x) #샘플 개수
w2_grad = np.dot(self.a1.T, err) / m #출력층 그레이디언트
b2_grad = np.num(err) / m
err_to_hidden = np.dot(err, self.w2.T) * self.a1 * (1 - self.a1) #시그모이드 그레이디언트 계산
w1_grad = np.dot(x.T, err_to_hidden) / m #은닉층 그레이디언트
b1_grad = np.sum(err_to_hidden) / m
return w1_grad, b1_grad, w2_grad, b2_grad 앞서 구한 공식을 코드로 표현한 것이다.
err_to_hidden은 가중치와 절편에서의 식이 동일하여 미리 값을 구해 계산과정을 간단하게 만들어 낸 것이다.
fit() 수정
def init_weights(self, n_featuers):
self.w1 = np.ones((n_featuers, self.units)) #(특성 개수, 은닉층 크기)
self.b1 = np.zeros(self.units) #은닉층 크기
self.w2 = np.ones((self.units, 1)) #(은닉층 크기,1)
self.b2 = 0
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
y = y.reshape(-1, 1)
y_val = y_val.reshape(-1, 1)
m = len(x)
self.init_weights(x.shape[1]) #가중치 초기화
for i on range(epochs):
a = self.training(x, y, m)
a = np.clip(a, 1e-10,1-1e-10) #클리핑
loss = np.sum(-(y*np.log(a) + (1-y)*np.log(1-a))) #로그 손실 추가
self.losses.append((loss + self.reg_loss()) / m)
self.update_val_loss(x_val, y_val)
def training(self, x, y, m):
z = self.forpass(x) #정방향 계산
a = self.activation(z) #활성화 함수
err = -(y - a) #오차 계산
w1_grad, b1_grad, w2_grad, b2_grad = self.backprop(x, err)
#그레이디언트 규제
w1_grad += (self.l1 * np.sign(self.w1) + self.l2 * self.w1) / m
w2_grad += (self.l1 * np.sign(self.w2) + self.l2 * self.w2) / m
#은닉층 가중치 절편 업데이트
self.w1 -= self.lr * w1_grad
self.b1 -= self.lr * b1_grad
#출력층 가중치 절편 업데이트
self.w2 -= self.lr * w2_grad
self.b2 -= self.lr * b2_grad
return a코드가 길어지고 가독성을 위해 가중치, 절편 초기화 함수와 훈련 코드를 분리하였다.
reg_loss() 수정
def reg_loss(self):
#은닉층과 출력층의 가중치에 규제 적용
return self.l1 * (np.sum(np.abs(self.w1)) + np.sum(np.abs(self.w2))) + self.l2 / 2 * (np.sum(self.w1**2) + np.sum(self.w2**2))
훈련 및 테스트
그래프로 분석해보자.
손실 그래프가 이전보다 천천히 감소한다.
SingleLayer 클래스보다 가중치의 개수가 훨씬 많아져 학습하는 데 시간이 오래 걸리기 때문이다.
breast_cancer데이터의 특성은 30개이므로 가중치 30개 절편 1개가 필요하지만,
DualLater 클래스에서는 뉴런(units)이 10개였으므로 30*10개의 가중치와 10개의 절편이 필요하고
출력층 역시 10개의 가중치와 1개의 절편이 필요하다. 총 321개의 가중치를 학습해야 한다.
가중치 초기화 개선
손실 그래프를 보면 초기 손실 값이 감소하는 곡선이 매끄럽지 않다.
아마도 손실 함수가 감소하는 방향을 올바르게 찾는 데 시간이 많이 소요된 것 같다.
가중치를 1로 놓고 훈련을 했던 것을 np.random.normal()을 이용하여 정규 분포를 따르는 무작위 수로 가중치를
초기화해보자.
class RandomInitNetwork(DualLayer):
def init_weights(self, n_featuers):
np.random.seed(42)
self.w1 = np.random.normal(0, 1, (n_featuers,self.units)) #(특성 개수, 은닉층 크기)
self.b1 = np.zeros(self.units) #은닉층 크기
self.w2 = np.random.normal(0, 1, (self.units, 1)) #(은닉층 크기, 1)
self.b2 = 0손실 함수가 감소하는 곡선이 매끄럽게 바뀌었다.
가중치를 1로 초기화했을 때 보다 훨씬 빠르게 손실 함숫값이 줄어들었다.