
미니 배치 사용
딥러닝에서는 종종 아주 많은 양의 데이터를 사용하는데 배치 경사 하강법은 모든 샘플을 처리해야 하기 때문에 적절하지 않을 수 있다. 따라서 확률적 경사 하강법과 배치 경사 하강법의 장점을 절충한 미니 배치(mini-batch) 경사 하강법이 널리 사용된다.
미니 배치 경사 하강법의 구현은 배치 경사 하강법과 비슷하지만 에포크마다 전체 데이터를 사용한느 것이 아니라 조금씩 나누어 정방향 계산을 수행하고 그레이디언트를 구하여 가중치를 업데이트한다.
보통 16, 32, 64 등의 2의 배수를 사용한다. 미니 배치의 크기가 1이라면 1개의 샘플씩 수행하는 것이기 때문에 확률적 경사 하강법과 동일하다. 배치 크기에 따라 확률적 경사 하강법과 배치 경사 하강법의 장점과 단점을 가지는 방법이다.
미니 배치의 크기가 충분히 크면 배치 경사 하강법처럼 안정적으로 손실함수를 최소화해 가지만 최적 값은 정해진 것이 아니다. 미니 배치의 크기도 하이퍼 파라미터이고 튜닝의 대상이다.
미니 배치 경사 하강법 구현
우선 클래스를 정의하자.
RandomInitNetwork를 상속받고 batch_size를 추가하여 만들어 보자.
class MinibatchNetwork(RandomInitNetwork):
def __init__(self, units=10, batch_size=32, learning_rate=0.1, l1=0, l2=0):
super().__init__(units, learning_rate, l1, l2)
self.batch_size = batch_size #배치 크기
fit() 메소드 수정
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
y_val = y_val.reshape(-1,1) #타깃 열 벡터로 변환
self.init_weights(x.shape[1]) #은닉층과 출력층 가중치 초기화
np.random.seed(42)
for i in range(epochs):
loss = 0
for x_batch, y_batch in self.gen_batch(x, y):
y_batch = y_batch.reshape(-1, 1) #타깃 열 벡터로 변환
m = len(x_batch)
a = self.training(x_batch, y_batch, m)
a = np.clip(a, 1e-10,1-1e-10) #클리핑
loss += np.sum(-(y_batch*np.log(a) + (1-y_batch)*np.log(1-a)))
self.losses.append((loss + self.reg_loss()) / len(x))
self.update_val_loss(x_val, y_val) #검증 손실 계산에포크를 순회하는 for문 안에 미니 배치를 순회하는 for문이 추가된다.
gen_batch() 메서드는 전체 훈련 데이터 x, y를 전달받아 batch_size만큼 미니 배치를 만들어 반환한다.
그 후 훈련을 진행한다.
gen_batch() 메소드 생성
def gen_batch(self, x, y):
length = len(x)
bins = length // self.batch_size #미니 배치 횟수
if length % self.batch_size: #나누어 떨어지지 않으면 1추가
bins += 1
indexes = np.random.permutation(np.arange(len(x))) #인덱스 셔플
x = x[indexes]
y = y[indexes]
for i int range(bins):
start = self.batch_size * i
end = self.batch_size * (i + 1)
yield x[start:end], y[start:end] #batch_size만큼 슬라이싱하여 반환
미니 배치 경사 하강법 적용
minibatch_net = MinibatchNetwork(l2=0.01, batch_size=32)
minibatch_net.fit(x_train_scaled, y_train, x_val = x_val_scaled, y_val= y_val, epochs=500)
minibatch_net.score(x_val_scaled,y_val)
plt.plot(minibatch_net.losses)
plt.plot(minibatch_net.val_losses)
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend(['train_loss', 'val_loss'])
plt.show()batch_size를 128로 늘려서 다시 진행해보고 비교해보자.
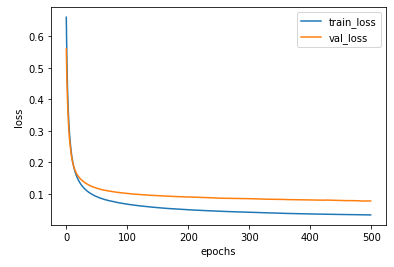 |
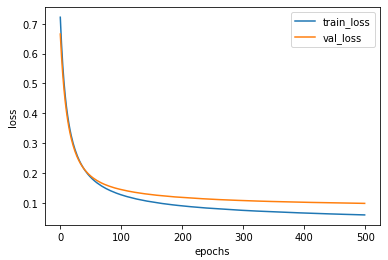 |
| batch_size = 32 | batch_size=128 |
batch_size를 늘렸더니 손실 그래프는 조금 더 안정적으로 바뀌었지만 손실값이 줄어드는 속도는 느려졌다.
일반적으로 미니 배치의 크기는 32~512개 사이의 값을 지정한다.
사이킷런 사용해 다층 신경망 훈련
사이킷런은 sklearn, neural_network 모듈 아래에 분류작업을 위한 MLPClassifier, 회귀 작업을 위한 MLPRegressor를 제공한다. cacner 데이터 세트에 MLPclassifier 클래스를 적용해 보자.
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier(hidden_layer_sizes=(10,), activation='logistic', solver='sgd', alpha=0.01, batch_size=32, learning_rate_init=0.1, max_iter=500)- 은닉층의 크기를 정의하는 hidden_layer_sizes
은닉층의 수와 뉴런의 개수를 튜플로 전달한다. 10개의 뉴런을 가진 2개의 은닉층은 hidden_layer_sizes(10, 10)이다. - 활성화 함수를 지정하는 activation
기본값은 ReLU이다. - 경사 하강법 알고리즘의 종류를 지정하는 매개변수 solver
기본값은 확률적 경사 하강법을 의미하는 sgd이다. - 규제를 적요하기 위한 alpha
L1규제는 효과가 크지 않아 사이킷런의 신경망 모델은 L2 규제만 지원한다. - 배치 크기, 학습률 초깃값, 에포크 횟수를 정하는 batch_size, learning_rate_init, max_iter
배치 크기를 정하는 batch_size (기본값 200), 학습률 초깃값 매개변수 learning_rate_init, 에포크 횟수 max_iter
훈련하기

성능이 조금 더 좋다.
구현하는데 조금 다른 부분이 있기 때문이다.
미니 배치 사용
딥러닝에서는 종종 아주 많은 양의 데이터를 사용하는데 배치 경사 하강법은 모든 샘플을 처리해야 하기 때문에 적절하지 않을 수 있다. 따라서 확률적 경사 하강법과 배치 경사 하강법의 장점을 절충한 미니 배치(mini-batch) 경사 하강법이 널리 사용된다.
미니 배치 경사 하강법의 구현은 배치 경사 하강법과 비슷하지만 에포크마다 전체 데이터를 사용한느 것이 아니라 조금씩 나누어 정방향 계산을 수행하고 그레이디언트를 구하여 가중치를 업데이트한다.
보통 16, 32, 64 등의 2의 배수를 사용한다. 미니 배치의 크기가 1이라면 1개의 샘플씩 수행하는 것이기 때문에 확률적 경사 하강법과 동일하다. 배치 크기에 따라 확률적 경사 하강법과 배치 경사 하강법의 장점과 단점을 가지는 방법이다.
미니 배치의 크기가 충분히 크면 배치 경사 하강법처럼 안정적으로 손실함수를 최소화해 가지만 최적 값은 정해진 것이 아니다. 미니 배치의 크기도 하이퍼 파라미터이고 튜닝의 대상이다.
미니 배치 경사 하강법 구현
우선 클래스를 정의하자.
RandomInitNetwork를 상속받고 batch_size를 추가하여 만들어 보자.
class MinibatchNetwork(RandomInitNetwork):
def __init__(self, units=10, batch_size=32, learning_rate=0.1, l1=0, l2=0):
super().__init__(units, learning_rate, l1, l2)
self.batch_size = batch_size #배치 크기
fit() 메소드 수정
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
y_val = y_val.reshape(-1,1) #타깃 열 벡터로 변환
self.init_weights(x.shape[1]) #은닉층과 출력층 가중치 초기화
np.random.seed(42)
for i in range(epochs):
loss = 0
for x_batch, y_batch in self.gen_batch(x, y):
y_batch = y_batch.reshape(-1, 1) #타깃 열 벡터로 변환
m = len(x_batch)
a = self.training(x_batch, y_batch, m)
a = np.clip(a, 1e-10,1-1e-10) #클리핑
loss += np.sum(-(y_batch*np.log(a) + (1-y_batch)*np.log(1-a)))
self.losses.append((loss + self.reg_loss()) / len(x))
self.update_val_loss(x_val, y_val) #검증 손실 계산에포크를 순회하는 for문 안에 미니 배치를 순회하는 for문이 추가된다.
gen_batch() 메서드는 전체 훈련 데이터 x, y를 전달받아 batch_size만큼 미니 배치를 만들어 반환한다.
그 후 훈련을 진행한다.
gen_batch() 메소드 생성
def gen_batch(self, x, y):
length = len(x)
bins = length // self.batch_size #미니 배치 횟수
if length % self.batch_size: #나누어 떨어지지 않으면 1추가
bins += 1
indexes = np.random.permutation(np.arange(len(x))) #인덱스 셔플
x = x[indexes]
y = y[indexes]
for i int range(bins):
start = self.batch_size * i
end = self.batch_size * (i + 1)
yield x[start:end], y[start:end] #batch_size만큼 슬라이싱하여 반환
미니 배치 경사 하강법 적용
minibatch_net = MinibatchNetwork(l2=0.01, batch_size=32)
minibatch_net.fit(x_train_scaled, y_train, x_val = x_val_scaled, y_val= y_val, epochs=500)
minibatch_net.score(x_val_scaled,y_val)
plt.plot(minibatch_net.losses)
plt.plot(minibatch_net.val_losses)
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend(['train_loss', 'val_loss'])
plt.show()batch_size를 128로 늘려서 다시 진행해보고 비교해보자.
|
|
| batch_size = 32 | batch_size=128 |
batch_size를 늘렸더니 손실 그래프는 조금 더 안정적으로 바뀌었지만 손실값이 줄어드는 속도는 느려졌다.
일반적으로 미니 배치의 크기는 32~512개 사이의 값을 지정한다.
사이킷런 사용해 다층 신경망 훈련
사이킷런은 sklearn, neural_network 모듈 아래에 분류작업을 위한 MLPClassifier, 회귀 작업을 위한 MLPRegressor를 제공한다. cacner 데이터 세트에 MLPclassifier 클래스를 적용해 보자.
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier(hidden_layer_sizes=(10,), activation='logistic', solver='sgd', alpha=0.01, batch_size=32, learning_rate_init=0.1, max_iter=500)- 은닉층의 크기를 정의하는 hidden_layer_sizes
은닉층의 수와 뉴런의 개수를 튜플로 전달한다. 10개의 뉴런을 가진 2개의 은닉층은 hidden_layer_sizes(10, 10)이다. - 활성화 함수를 지정하는 activation
기본값은 ReLU이다. - 경사 하강법 알고리즘의 종류를 지정하는 매개변수 solver
기본값은 확률적 경사 하강법을 의미하는 sgd이다. - 규제를 적요하기 위한 alpha
L1규제는 효과가 크지 않아 사이킷런의 신경망 모델은 L2 규제만 지원한다. - 배치 크기, 학습률 초깃값, 에포크 횟수를 정하는 batch_size, learning_rate_init, max_iter
배치 크기를 정하는 batch_size (기본값 200), 학습률 초깃값 매개변수 learning_rate_init, 에포크 횟수 max_iter
훈련하기
성능이 조금 더 좋다.
구현하는데 조금 다른 부분이 있기 때문이다.