
SimpleRNN
텐서플로에서 가장 기본적인 순환층은 SimpleRNN 클래스이다.
다음과 같이 만들 수 있다.
필요한 클래스 임포트하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN
모델 만들기
model = Sequential()
model.add(SimpleRNN(32, input_shape=(100, 100)))
model.add(Dense(1, activation='sigmoid'))
model.summary()

입력은 원-핫 인코딩 된 100차원 벡터이고 셀 개수가 32개이므로 W_1x 행렬 요소의 개수는 100 x 32가 된다.
W_1h 행렬의 요소 개수도 32 x 32가 된다. 마지막으로 셀마다 하나씩 총 32개의 절편이 있다.
모델 컴파일 & 훈련
model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(x_train_onehot, y_train, epochs=20, batch_size=32, validation_data=(x_val_onehot, y_val))plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.legend(['loss','val_loss'])
plt.show()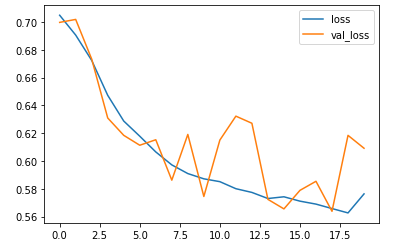
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['accuracy','val_accuracy'])
plt.show()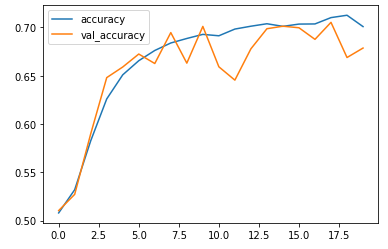
loss, accuracy = model.evaluate(x_val_onehot, y_val, verbose=0)
print(accuracy)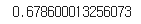
정확도가 높지 않다. 조금만 개선해서 성능을 향상해보자.
임베딩층으로 성능 높이기
순환 신경망의 가장 큰 단점 중 하나는 텍스트 데이터를 원-핫 인코딩으로 전처리한다는 것이다.
원-핫 인코딩을 사용하면 입력 데이터 크기와 사용할 수 있는 영단어의 수가 제한된다는 문제가 있다.
또 원-핫 인코딩은 '단어 사이에는 관련이 전혀 없다'는 가정이 전제되어야 한다.
예를 들어 boy와 girl은 연관이 있지만 관계를 잘 표현하지 못한다.
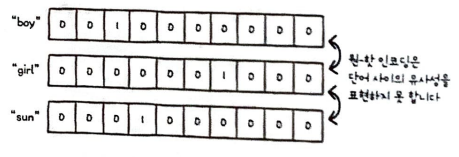
이런 문제를 해결하기 위해 고안된 것이 단어 임베딩(word embedding)이다.
단어 임베딩이란 단어를 고정된 길이의 실수 벡터로 임베딩 하는 것이다.
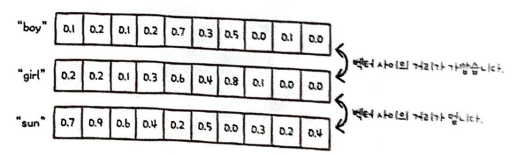
그림을 보면 boy와 girl을 구성하는 숫자들의 차이는 크지 않다.
반면 sun은 두 단어와 비교했을 때 숫자들의 차이가 크다.
이런 식으로 원-핫 인코딩을 변경한다면 성능을 올릴 수 있다.
Embedding 클래스 임포드
from tensorflow.keras.layers import Embedding
model2 = Sequential()
model2.add(Embedding(1000, 32))
model2.add(SimpleRNN(8))
model2.add(Dense(1, activation='sigmoid'))
model2.summary()model2.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history = model2.fit(x_train_seq, y_train, epochs=20, batch_size=32, validation_data=(x_val_seq, y_val))plt.plot(history2.history['loss'])
plt.plot(history2.history['val_loss'])
plt.legend(['loss','val_loss'])
plt.show()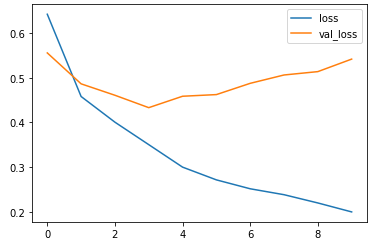
plt.plot(history2.history['accuracy'])
plt.plot(history2.history['val_accuracy'])
plt.legend(['accuracy','val_accuracy'])
plt.show()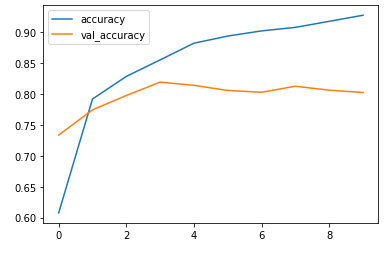
loss, accuracy = model2.evaluate(x_val_seq, y_val, verbose=0)
print(accuracy)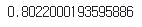
임베딩을 통해 성능을 20%나 향상했다.
SimpleRNN
텐서플로에서 가장 기본적인 순환층은 SimpleRNN 클래스이다.
다음과 같이 만들 수 있다.
필요한 클래스 임포트하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, SimpleRNN
모델 만들기
model = Sequential()
model.add(SimpleRNN(32, input_shape=(100, 100)))
model.add(Dense(1, activation='sigmoid'))
model.summary()
입력은 원-핫 인코딩 된 100차원 벡터이고 셀 개수가 32개이므로 W_1x 행렬 요소의 개수는 100 x 32가 된다.
W_1h 행렬의 요소 개수도 32 x 32가 된다. 마지막으로 셀마다 하나씩 총 32개의 절편이 있다.
모델 컴파일 & 훈련
model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(x_train_onehot, y_train, epochs=20, batch_size=32, validation_data=(x_val_onehot, y_val))plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.legend(['loss','val_loss'])
plt.show()plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['accuracy','val_accuracy'])
plt.show()loss, accuracy = model.evaluate(x_val_onehot, y_val, verbose=0)
print(accuracy)정확도가 높지 않다. 조금만 개선해서 성능을 향상해보자.
임베딩층으로 성능 높이기
순환 신경망의 가장 큰 단점 중 하나는 텍스트 데이터를 원-핫 인코딩으로 전처리한다는 것이다.
원-핫 인코딩을 사용하면 입력 데이터 크기와 사용할 수 있는 영단어의 수가 제한된다는 문제가 있다.
또 원-핫 인코딩은 '단어 사이에는 관련이 전혀 없다'는 가정이 전제되어야 한다.
예를 들어 boy와 girl은 연관이 있지만 관계를 잘 표현하지 못한다.
이런 문제를 해결하기 위해 고안된 것이 단어 임베딩(word embedding)이다.
단어 임베딩이란 단어를 고정된 길이의 실수 벡터로 임베딩 하는 것이다.
그림을 보면 boy와 girl을 구성하는 숫자들의 차이는 크지 않다.
반면 sun은 두 단어와 비교했을 때 숫자들의 차이가 크다.
이런 식으로 원-핫 인코딩을 변경한다면 성능을 올릴 수 있다.
Embedding 클래스 임포드
from tensorflow.keras.layers import Embedding
model2 = Sequential()
model2.add(Embedding(1000, 32))
model2.add(SimpleRNN(8))
model2.add(Dense(1, activation='sigmoid'))
model2.summary()model2.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
history = model2.fit(x_train_seq, y_train, epochs=20, batch_size=32, validation_data=(x_val_seq, y_val))plt.plot(history2.history['loss'])
plt.plot(history2.history['val_loss'])
plt.legend(['loss','val_loss'])
plt.show()plt.plot(history2.history['accuracy'])
plt.plot(history2.history['val_accuracy'])
plt.legend(['accuracy','val_accuracy'])
plt.show()loss, accuracy = model2.evaluate(x_val_seq, y_val, verbose=0)
print(accuracy)
임베딩을 통해 성능을 20%나 향상했다.