
열과 피벗
데이터프레임의 열은 파이썬의 변수와 비슷한 역할을 한다. 예를 들어 ebola 데이터프레임 열은 사망한 날짜(Date), 발병 국가(Case_Guinea) 등의 데이터를 저장하고 있다. 하지만 이번에 다루는 데이터프레임의 열은 열 자체가 어떤 값을 의미한다. 그러다 보니 데이터프레임의 열이 옆으로 길게 늘어선 형태가 된다. 바로 이것을 '넓은 데이터'라고 한다.
이를 깔끔하게 정리하려면 melt 메서드를 사용해야 한다.

melt 메서드의 인자를 정리한 표이다.
퓨 리서치 센터(Pew Research Center)에서 조사한 '미국의 소득과 종교'라는 데이터이다.
import pandas as pd
pew = pd.read_csv('../data/pew.csv')
print(pew.head())
각열은 소득구간으로 열 이름이 설정되어 있다. 만약 소득 정보 열을 행 데이터로 옮기고 싶다면 어떻게 해야 할까?
melt 메서드를 사용하면 된다.
pew_long = pd.melt(pew, id_vars='religion')
print(pew_long.head())
id_vars 인잣값으로 지정한 열을 제외한 나머지 소득 정보 열이 variable 열로 정리되고 소득정보 열의 행 데이터도 value 열로 정리되었다. 이 과정을 'religion 열을 고정하여 피벗 했다'라고 한다.
variable, value 열의 이름을 바꾸려면 var_name, value_name 인잣값을 사용하면 된다.
pew_long = pd.melt(pew, id_vars='religion', var_name='income', value_name='count')
print(pew_long.head())
2개 이상의 열을 고정할 수 있다. 빌보드 차트 데이터를 사용하여 알아보자.
billboard = pd.read_csv('../data/billboard.csv')
print(billboard.iloc[0:5, 0:16])
billboard_long = pd.melt(billboard, id_vars=['year', 'artist', 'track', 'time', 'date.entered'], var_name='week', value_name='rating')
print(billboard_long.head())
하나의 열이 여러 의미를 가지고 있는 경우
어떤 열은 여러 가지 의미를 가지고 있을 수 있다. 예를 들어 ebola 데이터 집합의 열중 하나인 Deaths_Guinea는 '사망자 수'와 '나라 이름'을 합쳐 만든 이름이다.
ebola = pd.read_csv('../data/country_timeseries.csv')
print(ebola.columns)
print(ebola.iloc[:5, [0, 1, 2, 3, 10, 11]])
Date와 Day를 고정하고 나머지를 행으로 피벗 하자.
ebola_long = pd.melt(ebola, id_vars=['Date', 'Day'])
print(ebola_long)
이제 split 메서드를 이용하여 2개 이상의 의미를 가지고 있는 열 이름을 분리해 보자.
기본적으로 공백을 기준으로 문자열을 자른다. 인자를 주어 특정 문자를 기준으로 분리하게 할 수 있다.
variable_split = ebola_long.variable.str.split('_')
print(variable_split[:5])
variable_split에 저장된 값의 자료형은 시리즈이고 각각의 시리즈에 저장된 값의 자료형은 리스트이다.
variable_split에 저장된 0번째 인덱스는 상태를 의미하고 1번째 인덱스는 나라 이름을 의미한다.
이제 이 문자열을 분리하여 데이터프레임의 새로운 열로 추가하면 된다.
status_values = variable_split.str.get(0)
country_values = variable_split.str.get(1)
print(status_values[:5])
ebola_long['status'] = status_values
ebola_long['country'] = country_values
print(ebola_long.head())
concat 메서드를 사용하면 간단하게 할 수 있다.
variable_split = ebola_long.variable.str.split('_', expand=True)
variable_split.columns = ['status', 'country']
ebola_parsed = pd.concat([ebola_long, variable_split], axis=1)
print(ebola_parsed.head())
여러 열을 하나로 정리하기
이번에는 반대로 비슷한 성질이 여러 열에 분리되어 있는 경우를 정리해보자.
기상 데이터를 불러와 날짜 열에는 각 월별 최고, 최저 온도 데이터가 저장되어 있다.
weather = pd.read_csv('../data/weather.csv')
print(weather.iloc[:5, :])
melt 메서드로 일별 온도 측정값을 피벗하자. day열에 날짜 열이 정리되고 날짜 열의 데이터는 temp열에 정리된다.
weather_melt = pd.melt(weather, id_vars=['id', 'year', 'month', 'element'], var_name='day', value_name='temp')
print(weather_melt.head())
이제 pivot_table 메서드를 사용해서 정리해보자. pivot_table 메서드는 행과 열의 위치를 다시 바꿔 정리해주는 메서드이다. index 인자에는 위치를 그대로 유지할 이름을 지정하고, columns 인자에는 피벗할 열 이름을 지정하고, values 인자에는 새로운 열의 데이터가 될 이름을 지정하면 된다.
weahter_tidy = weather_melt.pivot_table(
index=['id', 'year', 'month', 'day'],
columns=['element'],
values='temp'
)
print(weahter_tidy)
reset_index 메서드로 인덱스를 정리하자.
wether_tidy_flat = weahter_tidy.reset_index()
print(wether_tidy_flat)
중복 데이터 처리
빌보드 차트 데이터는 artist, track, time, date.entered 열의 데이터가 반복된다. 이런 반복되는 데이터는 따로 관리하는 것이 좋다.
billboard = pd.read_csv('../data/billboard.csv')
billboard_long = pd.melt(billboard, id_vars=['year', 'artist', 'track', 'time', 'date.entered'], var_name='week', value_name='rating')
print(billboard_long.head())
year, artist, track, time, date는 계속해서 반복 하기 때문에 따로 모아 데이터 프레임에 저장한다.
billboard_songs = billboard_long[['year', 'artist', 'track','time']]
print(billboard_songs)
drop_duplicates 메서드로 중복 데이터를 제거한다.
billboard_songs = billboard_songs.drop_duplicates ()
print(billboard_songs)
id를 추가하여 조회 성능을 올린다.
billboard_songs['id'] = range(len(billboard_songs))
print(billboard_songs.head(n=10))
merge 메서드를 사용해 노래 정보와 주간 순위 데이터를 합친다.
billboard_ratings = billboard_long.merge(billboard_songs, on=['year', 'artist', 'track', 'time'])
print(billboard_ratings)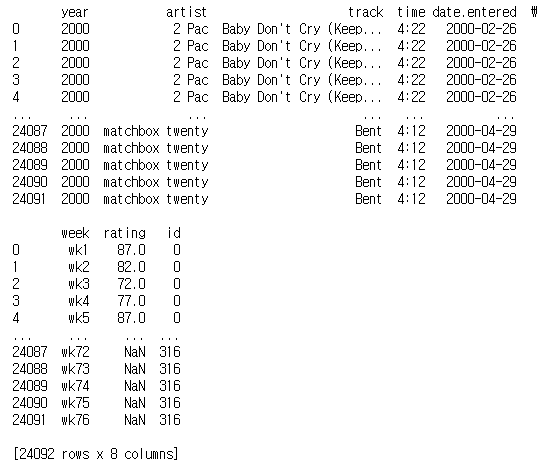
대용량 데이터 처리
데이터는 필요에 따라 나누어 저장하기도 한다. 데이터를 나누어 저장하면 용량이 작아져 데이터를 저장하거나 다른 사람에게 공유할 때 유용하다. 또 어떤 경우에는 처음부터 크기가 작은 데이터가 생성되는 경우도 있다.
예를 들어 주식 정보를 매일 수집한다면 일 단위로 데이터가 생성된다. 이를 한 번에 보려면 여러 개로 나누어진 데이터를 신속하게 불러와 처리해야 한다.
뉴욕 택시 데이터는 140개의 파일로 나누어져 있다. 이 중 5개만 사용해 보자.
import os
import urllib.request
with open('../data/raw_data_urls.txt', 'r') as data_urls:
for line, url in enumerate(data_urls):
if line == 5:
break
fn = url.split('/')[-1].strip()
fp = os.path.join('', '../data', fn)
print(url)
print(fp)
urllib.request.urlretrieve(url, fp)내려받은 데이터는 data 폴더에 'fhv_*'와 같은 형태로 저장된다.
glob 라이브러리에 포함된 glob 메서드는 특정한 패턴의 이름을 가진 파일을 한 번에 읽어 들일 수 있다.
import glob
nyc_taxi_data = glob.glob('../data/fhv_*')
print(nyc_taxi_data)이를 가지고 데이터프레임으로 지정한다.
taxi1 = pd.read_csv(nyc_taxi_data[0])
taxi2 = pd.read_csv(nyc_taxi_data[1])
taxi3 = pd.read_csv(nyc_taxi_data[2])
taxi4 = pd.read_csv(nyc_taxi_data[3])
taxi5 = pd.read_csv(nyc_taxi_data[4])데이터를 확인해보자.
print(taxi1.head(n=2))
print(taxi2.head(n=2))
print(taxi3.head(n=2))
print(taxi4.head(n=2))
print(taxi5.head(n=2))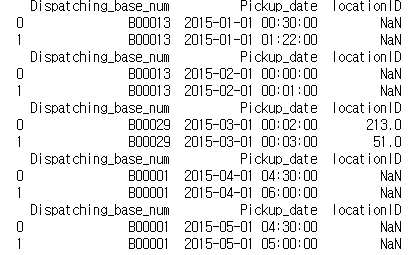
concat 메서드로 5개의 데이터프레임을 합쳐보자.
taxi = pd.concat([taxi1, taxi2, taxi3, taxi4, taxi5])
print(taxi.head(n=15))
반복문을 사용하면 더욱 간단하게 작업할 수 있다.
list_taxi_df = []
for csv_filename in nyc_taxi_data:
df = pd.read_csv(csv_filename)
list_taxi_df.append(df)
print(type(list_taxi_df[0]))
print()
print(list_taxi_df[0].head())
