
학습 곡선
훈련 세트와 검증 세트의 정확도를 그래프로 표현한 것이다.
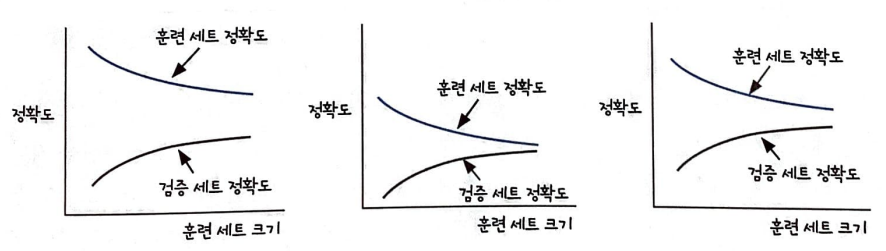
과대적합
과대적합이란 모델이 훈련 세트에서는 좋은 성능을 내지만 검증 세트에서는 낮은 성능을 내는 경우를 말한다.
첫 번째 그래프가 이에 해당한다.
이러한 모델을 '분산이 크다'라고도 말한다. 과대적합의 주요 원인 중 하나는 훈련 세트에 충분히 다양한 패턴의 샘플이 포함되지 않은 경우이다. 이런 경우네는 더 많은 훈련 샘플을 모아 검증 세트의 성능을 향상할 수 있다.
하지만, 불가능할 경우 모델이 훈련 세트에 집착하지 않도록 가중치를 제한하는 것이다.
이를 모델의 복잡도를 낮춘다고 표현한다.
과소적합
과소적합이란 모델이 훈련 세트와 검증 세트에서 측정한 성능이 가까워지지만 성능 자체가 낮은 경우를 말한다.
두 번째 그래프가 이에 해당한다.
이러한 모델을 '편향이 크다'라고도 말한다. 과소적합의 주요 원인은 모델이 충분히 복잡하지 않아 훈련 데이터에 있는 패턴을 모두 잡아내지 못하는 것이다.
이를 해결하려면 복잡도가 더 높은 모델을 사용하거나 가중치의 규제를 완화하는 것이다.
에포크와 손실 함수에서의 과대&과소 적합
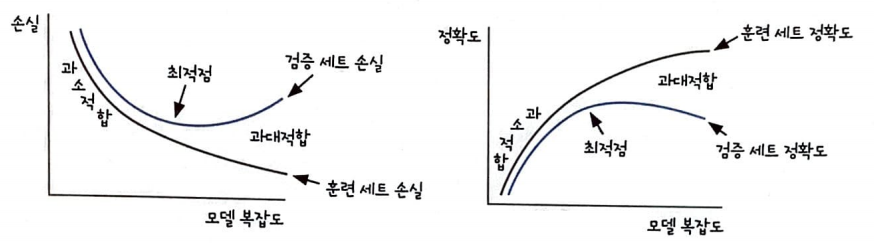
에포크가 증가하면서 훈련 세트 손실과 검증 세트 손실의 차이가 증가한다면 과대적합을 의심해야 한다.
최적점 이후에도 계속하여 훈련 세트로 모델을 학습시키면 모델이 훈련 세트에 더 밀착하여 학습한다.
마냥 많이 시킨다고 좋은 게 아니다.
반대로 최적점 이전에는 훈련 세트와 검증 세트의 손실이 비슷한 간격을 유지하며 줄어든다.
이대로 학습을 중지한다면 과소적합된 모델이 만들어진다.
그렇다고 에포크가 많거나 모델이 복잡하다고 무조건 좋은 모델이 만들어지지 않는다.
따라서, 적절한 에포크와 복잡도를 고려해야 한다.
편향-분산 Tradeoff
과소적합(편향이 크다) vs 과대적합(분산이 크다)
이 두 사이는 Tradeoff 관계에 있다.
분산이 너무 크지도 편향이 너무 크지도 않은 모델을 만들어야 한다
SingleLayer에 val_losses추가
def __init(self):
self.w = None
self.b = None
self.losses = []
self.val_losses = []
self.w_history = []
self.lr = learning_rate
fit() 메서드 변경
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
self.w = np.ones(x.shape[1]) #가중치 초기화
self.b = 0 #절편 초기화
self.w_history.append(self.w.copy()) #가중치 기록
np.random.seed(42)
for i in range(epochs):
loss = 0
indexes = np.random.permutation(np.arange(len(x)))
for i in indexes:
z = self.forpass(x[i]) #정방향 계산
a = self.activation(z) #활성화 함수
err = -(y[i] - a) #오차 계산
w_grad, b_grad = self.backprop(x[i], err) #역방향 계산
self.w -= self.lr * w_grad #가중치 업데이트
self.b -= b_grad #절편 업데이트
self.w_history(self.w.copy()) #가중치 기록
a = np.clip(a, 1e-10,1-1e-10) #클리핑
loss += -(y[i]*np.log(a)+(1-y[i])*np.log(1-a))
self.losses.append(loss/len(y)) #손실저장
self.update_val_loss(x_val, y_val) #검증세트 손실저장
def update_val_loss(self, x_val, y_val):
if x_val is None:
return
val_loss = 0
for i in range(len(x_val)):
z = self.forpass(x_val[i])
a = self.activation(z)
a = np.clip(a, 1e-10, 1-1e-10)
val_loss += -(y_val[i]*np.log(a)+(1-y_val[i])*np.log(1-a))
self.val_losses.append(val_loss/len(y_val))
검증 세트의 손실을 저장하여 어떻게 진행되는지 살펴보자.
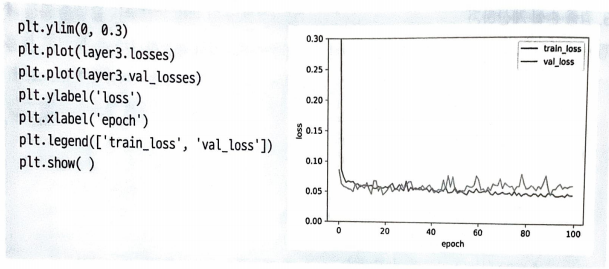
대략 20번째 에포크 이후 val_loss가 train_loss보다 높은 값을 보인다.
따라서, 더 이상 훈련 세트에 적응되지 않게 에포크를 20번만 주어 훈련하면 검증 세트의 성능을 높일 수 있다.
이를 조기 종료(early stopping)라고 부른다.
학습 곡선
훈련 세트와 검증 세트의 정확도를 그래프로 표현한 것이다.
과대적합
과대적합이란 모델이 훈련 세트에서는 좋은 성능을 내지만 검증 세트에서는 낮은 성능을 내는 경우를 말한다.
첫 번째 그래프가 이에 해당한다.
이러한 모델을 '분산이 크다'라고도 말한다. 과대적합의 주요 원인 중 하나는 훈련 세트에 충분히 다양한 패턴의 샘플이 포함되지 않은 경우이다. 이런 경우네는 더 많은 훈련 샘플을 모아 검증 세트의 성능을 향상할 수 있다.
하지만, 불가능할 경우 모델이 훈련 세트에 집착하지 않도록 가중치를 제한하는 것이다.
이를 모델의 복잡도를 낮춘다고 표현한다.
과소적합
과소적합이란 모델이 훈련 세트와 검증 세트에서 측정한 성능이 가까워지지만 성능 자체가 낮은 경우를 말한다.
두 번째 그래프가 이에 해당한다.
이러한 모델을 '편향이 크다'라고도 말한다. 과소적합의 주요 원인은 모델이 충분히 복잡하지 않아 훈련 데이터에 있는 패턴을 모두 잡아내지 못하는 것이다.
이를 해결하려면 복잡도가 더 높은 모델을 사용하거나 가중치의 규제를 완화하는 것이다.
에포크와 손실 함수에서의 과대&과소 적합
에포크가 증가하면서 훈련 세트 손실과 검증 세트 손실의 차이가 증가한다면 과대적합을 의심해야 한다.
최적점 이후에도 계속하여 훈련 세트로 모델을 학습시키면 모델이 훈련 세트에 더 밀착하여 학습한다.
마냥 많이 시킨다고 좋은 게 아니다.
반대로 최적점 이전에는 훈련 세트와 검증 세트의 손실이 비슷한 간격을 유지하며 줄어든다.
이대로 학습을 중지한다면 과소적합된 모델이 만들어진다.
그렇다고 에포크가 많거나 모델이 복잡하다고 무조건 좋은 모델이 만들어지지 않는다.
따라서, 적절한 에포크와 복잡도를 고려해야 한다.
편향-분산 Tradeoff
과소적합(편향이 크다) vs 과대적합(분산이 크다)
이 두 사이는 Tradeoff 관계에 있다.
분산이 너무 크지도 편향이 너무 크지도 않은 모델을 만들어야 한다
SingleLayer에 val_losses추가
def __init(self):
self.w = None
self.b = None
self.losses = []
self.val_losses = []
self.w_history = []
self.lr = learning_rate
fit() 메서드 변경
def fit(self, x, y, epochs=100, x_val=None, y_val=None):
self.w = np.ones(x.shape[1]) #가중치 초기화
self.b = 0 #절편 초기화
self.w_history.append(self.w.copy()) #가중치 기록
np.random.seed(42)
for i in range(epochs):
loss = 0
indexes = np.random.permutation(np.arange(len(x)))
for i in indexes:
z = self.forpass(x[i]) #정방향 계산
a = self.activation(z) #활성화 함수
err = -(y[i] - a) #오차 계산
w_grad, b_grad = self.backprop(x[i], err) #역방향 계산
self.w -= self.lr * w_grad #가중치 업데이트
self.b -= b_grad #절편 업데이트
self.w_history(self.w.copy()) #가중치 기록
a = np.clip(a, 1e-10,1-1e-10) #클리핑
loss += -(y[i]*np.log(a)+(1-y[i])*np.log(1-a))
self.losses.append(loss/len(y)) #손실저장
self.update_val_loss(x_val, y_val) #검증세트 손실저장
def update_val_loss(self, x_val, y_val):
if x_val is None:
return
val_loss = 0
for i in range(len(x_val)):
z = self.forpass(x_val[i])
a = self.activation(z)
a = np.clip(a, 1e-10, 1-1e-10)
val_loss += -(y_val[i]*np.log(a)+(1-y_val[i])*np.log(1-a))
self.val_losses.append(val_loss/len(y_val))
검증 세트의 손실을 저장하여 어떻게 진행되는지 살펴보자.
대략 20번째 에포크 이후 val_loss가 train_loss보다 높은 값을 보인다.
따라서, 더 이상 훈련 세트에 적응되지 않게 에포크를 20번만 주어 훈련하면 검증 세트의 성능을 높일 수 있다.
이를 조기 종료(early stopping)라고 부른다.