타이타닉 생존자 예측 kaggle에 있는 데이터 셋을 불러와 Tableau를 이용하여 분석해보자. 데이터 전처리를 한 뒤 모델에 학습을 시켜보자. 데이터 원본이다. 쭉 둘러보니 쓸모없는 데이터도 있는 것 같다. 성별과 나이를 분석해 봤다. 파란색이 여자, 주황색이 남자이다. 0이 죽은 사람, 1은 생존자이다. 눈에 확연히 들어오는 것은 20~30대의 남성이 여성에 비해 많이 죽었다는 것과 10~30대의 여성이 남성에 비해 많이 생존했다는 것이다. 원의 크기로 보아 남성 승객이 더 많았음을 알 수 있다. 또한 남색이 죽은 사람이고 주황색이 생존자이다. 여성은 남성에 비해 많이 탑승하지 않았지만 생존자가 죽은 사람보다 3배 많다. 그에 비해 남성은 많이 탑승하였지만 생존자가 4배 정도 적다. Pcalss를 ..
측정값 측정값이란 우리가 관심을 가지는 대상 그 자체이다. 예를 들어 타이타닉의 생존자를 분석한다든가 어느 회사의 매출, 수익, 사람들이 가장 많이 방문한 여행지는 무엇인지 등 여러 가지 관심을 가지는 대상이 있을 것이다. 이것이 측정값이다. 데이터 셋을 연결할 때 초록색 삼각형이 붙어있는 데이터는 문자열로 인식되었다는 뜻이다. 이런 값들은 차원으로 분류될 수 있다. 데이터를 불러들일때 설정하여 바꿔줄 수 있다. Abc부분을 눌러 숫자로 바꾸면 된다. 차원 차원은 우리가 관심을 가지는 측정값을 어떻게 나눠서 볼 것인가? 이다. 즉 데이터를 나누는 기준이 되는 것이다. 타이타닉의 생존자를 성별을 기준으로 분석할 것이다. 회사의 매출을 날짜별로 분석할 것이다. 등의 기준이 되는 것이다.
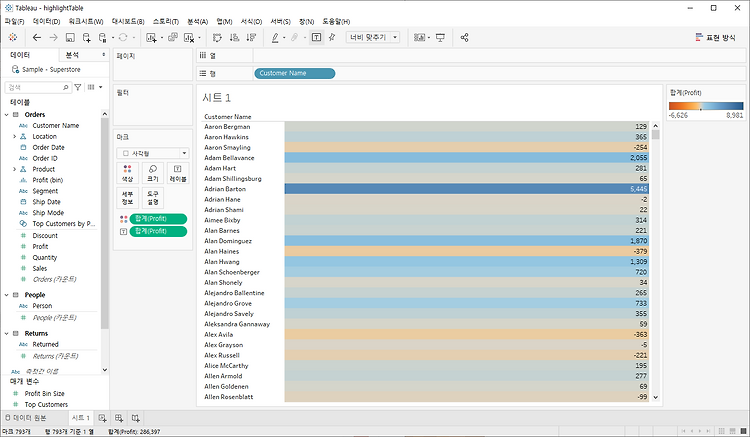
하이라이트 테이블(히트맵) 하이라이트 테이블을 그려보고 분석해보자. 하이라이트 테이블은 히트맵이라고도 한다. 하이라이트 테이블은 하나이상의 차원과 한 개의 측정값이 필요하다. 딱히 특별할 것은 없다. 그저 테이블인데 색이 칠해진 테이블이다. 합계 정보를 색으로 표시했다. 다른 정보들도 같이 표시해보자. 3개의 시리즈가 같은 색을 사용하고 있어 눈에 잘 들어오지 않는다. 이를 변경해보자. Quantity, Discount, Sales와 같이 한 방향으로 진행되는 데이터인 경우 단일 색상으로 이루어진 컬러를 적용하는 것이 좋고 Profit과 같이 양방향으로 진행되는 경우 다중 색상을 사용하는 것이 효과적이다. 트리 맵(Tree map) 한 개 이상의 차원과 한개 또는 두개의 측정값으로 표현하는 차트이다. 크..
Scatter plot 상관관계를 나타내는 scatter plot은 점으로 데이터를 표현한다. 수익과 할인율이 관계가 있을 거라 생각하고 그래프를 그려보자. 점이 하나 찍혀있다. 모든 물건에 대해 300,000원 정도의 수익이 났고 16% 정도 할인해 주었다는 뜻이다. 하지만 우리가 원하는 데이터는 이게 아니다. 고객별로 데이터를 나눠보자. 각 점은 고객에 대한 데이터이고 할인율과 수익을 볼 수 있다. 눈에 좀 더 잘 보이고 수익을 가져다주는 고객과 그렇지 않은 고객으로 분류해보자. 이것은 제품별로 본 것이다. 추세선을 추가하여 두 데이터사이에 관계를 볼 수 있다. Histogram 데이터 분포를 볼 수 있는 그래프이다. 데이터는 총 9994개의 행을 가지고 있다. 0에서 200달러 사이에 판매된 재품이..
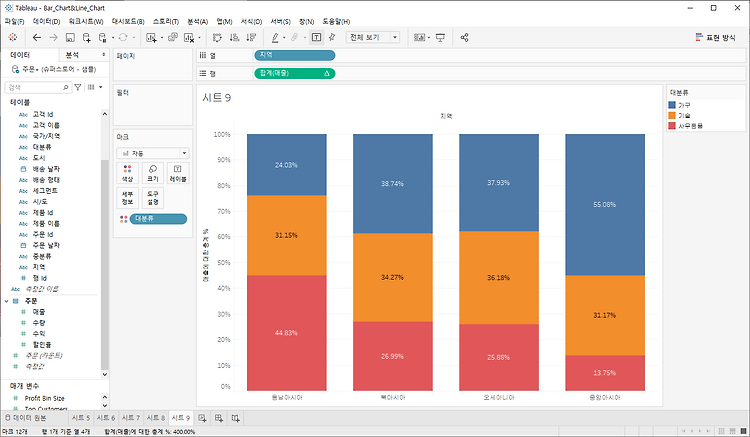
파이 차트 비율을 나타내는 차트 중 대표적인 차트이다. 동그란 그래프를 비율별로 나누어 가지게 된다. 이 그래프를 좀 더 보기 좋게 바꿔보자. 구성 비율에 대한 그래프이기 때문에 전체 금액보다는 %로 표현하는 것이 좋아 보인다. 또한 이런 그래프를 지역별로 보고 싶다면 왼쪽 지역 차원을 행이나 열로 끌어 당기면 된다 이 차트는 전체의 합이 100%가 된다. 누적이 아닌 각 지역별의 차트를 보는 게 좀 더 효과적일 것 같다. 특정 테이블 계산을 설정하면 변경할 수 있다. 하지만 아직까지 눈에 잘 들어오지는 않는다. 이를 더 좋게 바꾸는 것은 쉽지 않다. 따라서 전문가들은 파이차트를 추천하지 않는다. 이에 대한 대안이 비율 바 차트이다. 비율 바 차트 이와 같이 각도가 아닌 길이로 나타내는 비율 바 차트가 ..
바 차트(Bar Chart) 차트 중 가장 기본이 되는 막대그래프를 그려보자. 차원과 측정값을 적절히 지정하면 간단하게 그래프를 그릴 수 있다. 지역을 차원으로 매출을 측정값으로 지정하면 자동으로 바 차트를 그려준다. 데이터가 누워있는거 보단 위아래로 긴 차트가 좀 더 비교하기 쉬울 것 같다. 행과 열을 바꿔보자. 상단에 행과 열을 바꾸는 아이콘을 누르거나 ctrl + w를 누르면 돌릴 수 있다. 조금 더 눈에 잘 보이게 서식을 바꿔보자. 축 눈금자를 없애고 테두리를 입혀봤다. 라인 차트(Line Chart) 연속적인 데이터를 보기 쉬운 라인 차트를 그려보자. 라인 차트를 그릴 때는 날짜를 기준으로 분류하는게 일반적이다. 따라서 열에 주문 날짜를 행에 매출을 주어 그래프를 그리면 자동으로 라인 차트를 그..
데이터 불러오기 Tableau를 통해 데이터 시각화를 해보자. 그러려면 데이터를 우선 불러와야 한다. excel파일로 갖고 있는 데이터도 있을 것이고 server에서 다운로드할 수도 있다. 차근차근 데이터를 불러와 보자. Tableau에서 제공하는 데이터 샘플이 있다. 왼쪽 아래에 보면 '저장된 데이터 원본'이라는 문구를 볼 수 있다. 그 아래에 나오는 데이터들이 기본 샘플이다. 아무거나 하나 눌러보자. 데이터를 준비하는 창을 건너띄고 바로 작업할 수 있게 된다. 왼쪽 태블로 마크를 누르면 다시 데이터를 로드할 수 있는 창으로 돌아간다. 이러한 샘플들 말고도 txt, json 등 여러 파일 형태를 지원한다. 원본이 아닌 xls 파일이나 다른 파일들을 선탯하면 데이터를 준비하는 창을 볼 수 있다. 자신이 ..
문자열 다루기 문자열은 작은따옴표나 큰따옴표로 감싸서 만든다. 문자열은 인덱스를 갖고 있고 이를 통해 접근이 가능하다. word = 'grail' sent = 'a scratch' print(word[0]) print() print(sent[0]) 인덱스 슬라이싱을 사용하면 여러 개의 문자를 한 번에 추출할 수 있다. print(word[0:3]) 음수를 적용하면 -1이 마지막 문자이다. print(sent[0:-8]) 왼쪽과 오른쪽 중 하나만 지정하게 되면 마지막 위치까지 모두 추출한다. print(word[:3]) 문자열 메서드 문자열에 대한 작업을 하는 메서드가 여러 개 있다. 모두 소문자로 변환하거나 대문자로 변환하는 등 자주 사용되는 메서드를 봐보자. join 메서드 join 메서드는 문자열을 ..
자료형 다루기 자료형 변환은 데이터 분석 과정에서 반드시 알아야 하는 요소 중 하나이다. 예를 들어 카테고리는 문자열로 변환해야 데이터 분석을 수월하게 할 수 있다. 또 다은 예는 전화번호는 보통 숫자로 저장한다. 하지만 전화번호로 평균을 구하거나 더하는 등의 계산은 거의 하지 않는다. 오히려 문자열처럼 다루는 경우가 더 많다. 데이터를 준비하자. import pandas as pd import seaborn as sns tips = sns.load_dataset("tips") 자료형을 변환하려면 astype 메서드를 사용하면 된다. 다음은 astype 메서드를 사용해 sex 열의 데이터를 문자열로 변환하여 sex_str이라는 새로운 열에 저장한 것이다. tips['sex_str'] = tips['sex..
통계 계산 기초 데이터를 가지고 몇 가지 기초적인 통계 계산을 해보자. 갭마인더 데이터 집합에서 0~9번째 데이터를 추출한 것이다. print(df.head(n=10)) lifeExp 열을 연도별로 그룹화하여 평균 계산 데이터를 year열로 그룹화하고 lifeExp 열의 평균을 구하면 된다. 데이터프레임의 groupby 메서드에 year 열을 전달하여 연도별로 그룹화한 다음 lifeExp 열을 지정하여 mean 메서드로 평균을 구하자. print(df.groupby('year')['lifeExp'].mean()) lideExp, gdpPercap 열의 평균값을 연도, 지역별로 그룹화 year, continent 열로 그룹화한 그룹 데이터프레임에서 lifeExp, gdpPercap 열만 추출하여 평균을 구..