몽고 DB 몽고디비는 대표적인 NoSQL이다. NoSQL이란 SQL을 사용하지 않는다는 말이다. SQL과 차이점은 다음과 같다. NoSQL에는 고정된 테이블이 없다. 따라서 컬럼을 따로 정의하지는 않는다. 예를 들어 MySQL은 users 테이블을 만들 때, name, age, married 등의 컬럼과 자료형, 옵션을 정의한다. 몽고디비는 그냥 users 컬렉션을 만들고 끝낸다. 또한, 몽고디비에는 JOIN기능이 없다. 하지만, 확장성과 가용성이 뛰어나 많이 사용되고 있다. MySQL에서의 테이블, 로우, 컬럼은 몽고디비에서 컬렉션, 다큐먼트, 필드라고 부른다. 또한, 자바스크립트 문법을 사용한다. 노드도 자바스크립트를 사용하므로 데이터베이스마저 몽고디비를 사용한다면 자바스크립트만 사용하여 웹 애플리케..
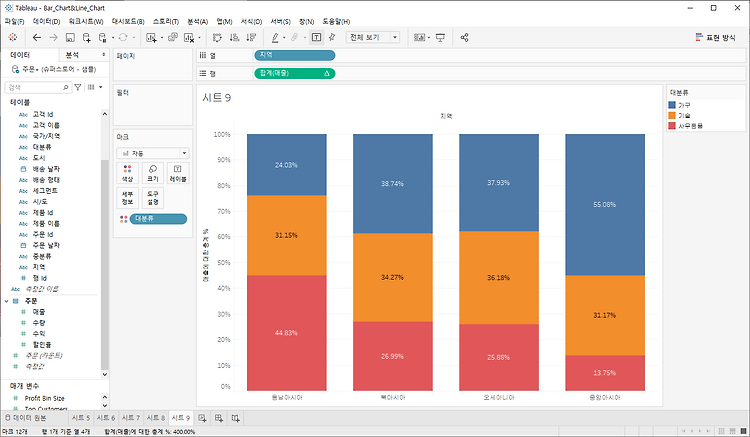
파이 차트 비율을 나타내는 차트 중 대표적인 차트이다. 동그란 그래프를 비율별로 나누어 가지게 된다. 이 그래프를 좀 더 보기 좋게 바꿔보자. 구성 비율에 대한 그래프이기 때문에 전체 금액보다는 %로 표현하는 것이 좋아 보인다. 또한 이런 그래프를 지역별로 보고 싶다면 왼쪽 지역 차원을 행이나 열로 끌어 당기면 된다 이 차트는 전체의 합이 100%가 된다. 누적이 아닌 각 지역별의 차트를 보는 게 좀 더 효과적일 것 같다. 특정 테이블 계산을 설정하면 변경할 수 있다. 하지만 아직까지 눈에 잘 들어오지는 않는다. 이를 더 좋게 바꾸는 것은 쉽지 않다. 따라서 전문가들은 파이차트를 추천하지 않는다. 이에 대한 대안이 비율 바 차트이다. 비율 바 차트 이와 같이 각도가 아닌 길이로 나타내는 비율 바 차트가 ..
시계열 데이터 시계열 데이터는 데이터 분석 분야에서 중요하게 다루는 데이터 중 하나이다. 일정 시간 간격으로 어떤 값을 기록한 데이터에서 시계열 데이터가 매우 중요하다. Datetime 오브젝트 datetime 라이브러리는 날짜와 시간을 처리하는 등의 다양한 기능을 제공하는 파이썬 라이브러리이다. datetime 라이브러리에는 날짜를 처리하는 date 오브젝트, 시간을 처리하는 time 오브젝트, 날짜와 시간 모두 처리하는 datetime 오브젝트가 포함되어 있다. from datetime import datetime now1 = datetime.now() print(now1) now2 = datetime.today() print(now2) now, today 메서드를 사용하면 현재 시간을 출력할 수 있..
데이터 집계 보통 그룹 연산은 데이터를 '분할'하고 '반영'하고 '결합'하는 과정을 거치게 된다. 이를 '분할 - 반영 - 결합(Split - Apply - Combine)'이라고 한다. groupby 메서드를 이용하여 뎅;터를 집계할 수 있다. 집계란 데이터에 평균을 구하거나 합을 구하는 등의 의미 있는 값을 도출해 내는 것을 말한다. import pandas as pd df = pd.read_csv('../data/gapminder.tsv', sep='\t') avg_life_exp_by_year = df.groupby('year').lifeExp.mean() print(avg_life_exp_by_year) groupby 메서드를 사용해 lifeExp 열의 연도별 평균값을 구했다. groupby 메..
apply 메서드 apply 메서드는 사용자가 작성한 함수를 한 번에 데이터프레임의 각 행과 열에 적용하여 실행할 수 있게 해주는 메서드이다. 즉, 함수를 브로드캐스팅해야 하는 경우에 apply 메서드를 사용한다. 함수를 하나 만들어 보자. def my_sq(x): return x ** 2 def my_exp(x, n): return x ** n print(my_sq(4)) print() print(my_exp(2, 4)) 이제 apply 메서드를 사용해보자. import pandas as pd df = pd.DataFrame({'a': [10, 20, 30], 'b':[20, 30, 40]}) print(df) print(df['a'] ** 2) 하나하나 적용할 수 있지만 아까 정의해 놓은 함수를 ap..
열과 피벗 데이터프레임의 열은 파이썬의 변수와 비슷한 역할을 한다. 예를 들어 ebola 데이터프레임 열은 사망한 날짜(Date), 발병 국가(Case_Guinea) 등의 데이터를 저장하고 있다. 하지만 이번에 다루는 데이터프레임의 열은 열 자체가 어떤 값을 의미한다. 그러다 보니 데이터프레임의 열이 옆으로 길게 늘어선 형태가 된다. 바로 이것을 '넓은 데이터'라고 한다. 이를 깔끔하게 정리하려면 melt 메서드를 사용해야 한다. melt 메서드의 인자를 정리한 표이다. 퓨 리서치 센터(Pew Research Center)에서 조사한 '미국의 소득과 종교'라는 데이터이다. import pandas as pd pew = pd.read_csv('../data/pew.csv') print(pew.head())..
분석하기 좋은 데이터 분석하기 좋은 데이터란 데이터 집합을 분석하기 좋은 상태로 만들어 놓은 것을 말한다. 데이터 분석 단계에서 데이터 정리는 아주 중요하다. 실제로 데이터 분석 작업의 70% 이상을 차지하고 있는 작업이 데이터 정리 작업이다. 분석하기 좋은 데이터는 다음 조건을 만족해야 하고 이러한 데이터를 Tidy Data라고 한다. 데이터 연결 예를 들어 주식 데이터를 분석하는 과정에서 '기업 정보'가 있는 데이터 집합과 '주식 가격'이 있는 데이터 집합이 있을 때 '첨단 산업 기업의 주식 가격에 대한 데이터'를 보려면 어떻게 해야 할까?? 일단 기업 정보에서 첨단 기술을 가진 기업을 찾아야 한다. 그리고 이 기업들의 주식 가격을 찾아야 한다. 그런 다음 찾아낸 2개의 데이터를 연결하면 된다. 이렇..
데이터 처리 열의 자료형을 바꾸거나 새로운 열을 추가하는 방법을 알아보자. print(scientists['Born'].dtype) print(scientists['Died'].dtype) 날짜를 문자열로 저장한 데이터는 시간 관련 작업을 할 수 있도록 datetime 자료형으로 바꾸는 것이 좋다. born_datetime = pd.to_datetime(scientists['Born'], format='%Y-%m-%d') print(born_datetime) died_datetime = pd.to_datetime(scientists['Died'], format='%Y-%m-%d') print(died_datetime) 이제 추가를 해보자. scientists['born_dt'], scientists['d..
통계 계산 기초 데이터를 가지고 몇 가지 기초적인 통계 계산을 해보자. 갭마인더 데이터 집합에서 0~9번째 데이터를 추출한 것이다. print(df.head(n=10)) lifeExp 열을 연도별로 그룹화하여 평균 계산 데이터를 year열로 그룹화하고 lifeExp 열의 평균을 구하면 된다. 데이터프레임의 groupby 메서드에 year 열을 전달하여 연도별로 그룹화한 다음 lifeExp 열을 지정하여 mean 메서드로 평균을 구하자. print(df.groupby('year')['lifeExp'].mean()) lideExp, gdpPercap 열의 평균값을 연도, 지역별로 그룹화 year, continent 열로 그룹화한 그룹 데이터프레임에서 lifeExp, gdpPercap 열만 추출하여 평균을 구..
데이터 추출 head() 메서드를 이용해 데이터프레임에서 가장 앞에 있는 5개의 데이터를 추출하여 출력했다. 데이터를 열 단위로 추출하는 방법과 행 단위로 추출하는 방법을 알아보자. 열 단위 데이터 추출 데이터프레임에서 데이터를 열 단위로 추출하려면 대괄호와 열 이름을 사용해야 한다. 이때 열 이름은 꼭 작은따옴표를 사용해서 지정해야 하고 추출한 열은 변수에 저장해서 사용한다. 이때 1개의 열만 추출하면 시리즈를 얻을 수 있고 2개 이상의 열을 추출하면 데이터프레임을 얻을 수 있다. country_df = df['country'] print(type(country_df)) print(country_df.head()) print(country_df.tail()) 대괄호와 열 이름으로 데이터를 추출하여 co..